Lock-Free
Lock-Free
什么是Lock-Free
Lock-Free也叫LockLess也就是无锁编程,它是一种在多线程之间安全的共享数据的一种方式,并且不需要有获取和释放锁的开销。但是不使用锁来进行编程却只是无锁编程的一部分。我们先用一个图来看看如何判断是不是无锁编程:
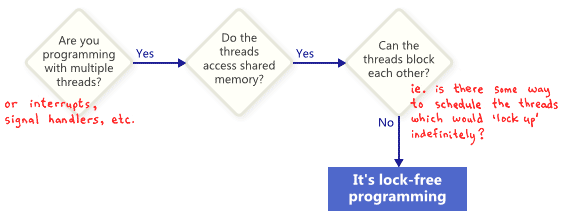
从这个图上可以看出,无锁编程中的锁并不是直接指向lock或者说mutex,而是指一种把整个程序锁住的可能性,无论是死锁还是活锁,甚至是因为你做了你能想到的最差的线程调度决策。如此一来,即使是共享锁也被排除在外。因为当你用std::shared_lock<std::shared_mutex> lock(mutex_); 拿到锁之后,你可以简单地再也不调度这个线程,来导致 std::unique_lock<std::shared_mutex> lock(mutex_);永远得不到锁。
下面这个例子中我们不使用mutex和lock,但是它依然不是Lock-Free,因为你可以调度执行这个函数的两个线程使得它俩都不退出循环。
1 | while (X == 0) |
我们并不会期望整个大程序都是Lock-Free,通常我们会指明其中某些操作是Lock-Free的,比如一个队列的实现中,我们会存在少数的Lock-Free操作,比如push,pop 等等。
Lock-Free的一个重要的结论是,当你暂停一个线程的运行,它并不会阻止其他线程继续执行,其他线程就像一个整体,继续他们的Lock-Free操作。这也是Lock-Free编程的价值,特别是当你编写中断处理程序、实时系统时,他们必须在规定的时间内完成任务,无论程序的其他部分怎么执行。
注意,假如我们是故意把部分操作设计成阻塞形式的,那么这并不会让程序中的算法不再Lock-Free。比如我们故意把pop设计成空的时候阻塞等待,那么我们依然可以声称程序的其他部分依然是Lock-Free的(比如pop中非空时候的算法逻辑)。
Lock-Free虽然是一种很有效的多线程编程技术,但是它不应该被轻易的使用。使用它之前你必须理解它的复杂性,并且仔细的确认它真的能给你带来你期望的收益。在很多情况下,通常存在更简单和快捷的解决方案,比如减少数据共享的频率。同时正确和安全的使用无锁编程需要对你使用的硬件(处理器)和编译器有较多的知识。
Lock-Free的技术要点
事实证明,当你试图编写满足Lock-Free条件的程序时,一系列的技术向你袭来: 原子操作,内存屏障, ABA问题等。这让整个事情变得不那么好玩了。
下面我会分别介绍这些技术点,并在最后用一幅图来表示这些技术之间的关系。
原子性R-M-W操作
原子操作指的是一系列不可分割的操作,其他线程无法看到这一系列操作的中间状态。现代处理器上,一些操作已经保证是原子性的,比如读写简单变量,比如赋值一个int类型的变量,是原子性的。然而对简单变量的原子性操作其实是有条件的,一个是内存对齐,一个是字节大小要小于等于总线宽度。我简单解释一下,数据总线在读写数据时总是根据总线宽度一次获取一定大小的数据,我们的简单变量的大小只要是小于等于总线宽度的,总线只需要操作一次。但是总线读取数据时总是内存对齐的,比如总线宽度为8则总是以8的倍数来读取,07,815,16~23,所以如果我们的简单变量的内存地址没有和8对齐,那么操作4字节的变量就可能需要两次才能完成,8字节的变量一定需要两步才能完成。因此中间可能会被打断,造成不是原子性的。对于内存对齐,我们平常的使用中以下代码都是可以自动保证对齐的,不需要担心:
1 | // 以64位机器为例,总线宽度即是8字节 |
因此对于32bit机器的long long和double,以及23bit和64bit的long double类型,我们不能确保原子性。但是你可能要说了,我们平时32位机器从来没为double和long long加过锁啊。是的,那是因为intel x86的处理器为我们增加了8字节的保证,确保32bit系统依然可以保证64位内存读取的原子性。其他处理器是没有这个保证的。
参考intel reorder的文档.
1 |
|
因此对于单步读写、且在x86/x64上,除了long double类型,其他都是原子性的操作。
而对于多步的RMW(读改写)的原子操作,如果我们采用Lock-Free的话该怎么做呢?
不同的CPU采用不同的方式来支持原子操作,有的采用LL+SC,有的采用CAS,两者效果是等价的。
原子RMW操作是Lock-Free中不可或缺的一部分,没有原子操作,即使程序只在单个处理器上运行,依然会有问题,因为RMW运行中途可能会发生线程切换,导致中间状态被其他线程看到,产生与并发时同样的问题
CAS循环
最常被讨论的RMW问题应该是CAS(compare-and-swap)了。
编程者通常重复循环执行CAS来达成某个操作。这个过程典型的步骤是,先拷贝一个共享的变量到一个本地的变量,再根据需要执行一些特殊的操作,然后尝试写一个共享变量。
1 | // |
这样的循环依旧是Lock-Free的,因为当compare_exchange_weak返回false时意味着另一个线程操作成功了。
关于compare_exchange_weak返回false的原因,除了campare失败(此时意味着另一个线程成功了)其实还可能是其他原因,这是因为cas在有些平台上是有多条指令来实现的(x86是只有一条指令的),线程切换、地址被其他线程使用都会导致指令失败。不过好在这也只是导致多执行几次while循环。
参考这个问题 Understanding std::atomic::compare_exchange_weak() in C++11
我们也可以换成compare_exchange_strong,不过放在while循环中,用weak就足矣,会比strong版本效率高些。
在使用CAS循环时,要特别注意ABA问题。
1 | void pop_front(){ |
假设目前链表中包含A->B->C这3个元素,当我这个线程运行至while中p->next取到B之后,另一个线程完成了弹出A、弹出B、释放B、插入A、这4个操作,行云流水一气呵成,这时候你开始执行你的CAS操作,m_head的值不变,于是你把m_head跟新成了B。显然出问题了,B已经被另一个线程释放了。这就是ABA问题。
顺序一致性
顺序一致性是指所有线程都遵从一定的指令执行顺序,这个顺序与源代码顺序一致。反之,顺序不一致则表示指令执行顺序与源代码不一致。
我们通过一个例子来验证顺序一致性问题的存在。
假设我们有以下4个整数:
1 | int x=0; |
另外有两个线程:
1 | void thread1(){ |
这两个线程并发执行,那么最后r1和r2可能的取值是什么?
可以想到的是(1,0),(0,1),(1,1)这几个结果。那么有没有可能出现(0,0)呢?
什么情况下才会出现(0,0)的结果,下面是其中一种执行顺序。

也就是说thread1和thread2中的代码顺序必须发生颠倒,才能出现(0,0)的结果。
然后我在主线程中增加一个循环来执行thread1和thread2,然后检查r1和r2的值。
1 | int count = 0; |
点此查看完整代码
我得到了这样的结果:
1 | ... |
发生概率略大于1/200.可见情况发生了。而能够产生乱序的原因有两个,一个是编译器优化,一个是cpu乱序。我首先插入代码来阻止编译器优化,阻止编译器擅自调换代码的顺序。
1 | void thread1(){ |
asm volatile("" ::: "memory");这行代码可以阻止编译器的优化,且不会插入任何汇编代码。发现执行结果没有改变,所以原因和编译器无关。
内存屏障
上面例子中,阻止内存乱序发生的方法是在两条指令之间引入CPU屏障或者说内存屏障。在不同的处理器中,内存屏障的指令是不同的,x86/x64中可以使用mfence指令。
1 | void thread1(){ |
最后乱序消失了。
这里mfence就是内存屏障了,mfence属于全功能的屏障,可以阻止指令上下的代码发生乱序。除了全功能屏障,还有Acquire和Release。
Acquire应用于读操作,可以是单纯的读或者是属于RMW中的R,Acquire紧跟读操作,它可以阻止该读操作与随后的所有的读写指令乱序。
Release应用于写操作,可以是单纯的写或者是RMW中的W,Release指令后紧跟写操作,它可以阻止该写操作与任何之前的读写指令乱序。
1 | //http://preshing.com/20120913/acquire-and-release-semantics/ |
Acquire和Release会比全功能的屏障更轻量一些。注意Acquire和Release指的是语义,不同平台有不同的指令来实现,x86和x64甚至是不提供的,因为天生就自带该语义。
我们可以看到Acquire可以隔绝(读,读),(读,写)之间的指令;Release可以隔绝(读,写)和(写,写)之间的指令;但是却都不能隔绝(写,读)指令。(写,读)指令的屏障相对更昂贵,x86和x64虽然天生自带Acquire和Release语义,但是对于写、读指令的屏障也只能mfence指令来实现,相对来说其他3个场景则不需要额外指令,简单多了。我们上面的例子就是一个(写,读)场景。
单处理器
还有一个简单但不切实际的方式来达到顺序一致性是禁用编译器优化(前面讲了禁用优化的指令),并且绑定你的所有线程到同一个处理器上。
那么为什么单处理器上的指令不会有乱序执行的问题?因为这是CPU乱序机制基本的保证,处理器不是不做乱序,而是它清楚的知道自己的乱序情况,因而可以很聪明的来避免会带来副作用的乱序操作。可以看这个问题Why doesn’t the instruction reorder issue occur on a single CPU core。
总结
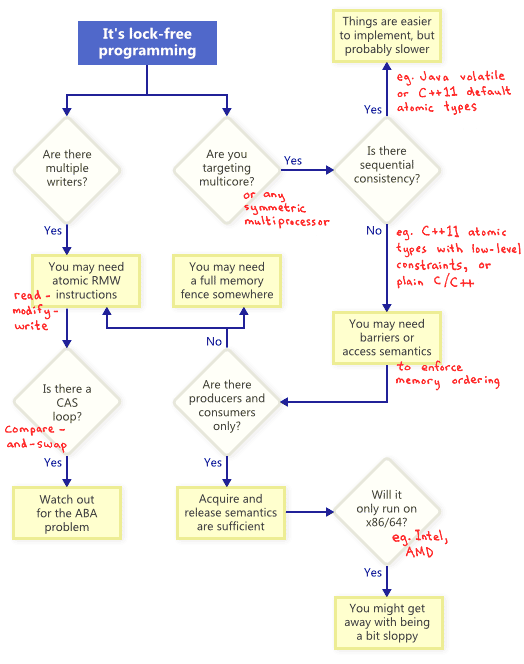
最后我用一张图来表示Lock-Free,RMW,CAS,顺序一致性,内存屏障之间的关系。
(图片版权归原作者所有)
参考资料
[1]an-introduction-to-lock-free-programming
[2]acquire-and-release-semantics
[3][Lockless Programming Considerations for Xbox 360 and Microsoft Windows][locklessmsurl]
[locklessmsurl]: https://msdn.microsoft.com/en-us/library/windows/desktop/ee418650(v=vs.85).aspx