LVS的原理-工作模式
LVS简介
什么是LVS:
1 | LVS是Linux Virtual Server的简写,意即Linux虚拟服务器,是一个虚拟的服务器集群系统。本项目在1998年5月由章文嵩博士成立,是中国国内最早出现的自由软件项目之一. |
LVS的作用:
LVS的原理很简单,当用户的请求过来时,会直接分发到LVS机器(director server)上,然后它把用户的请求根据设置好的调度算法,智能均衡地分发到后端真正服务器(real server)上。
简单的讲,LVS就是一种负载均衡服务器。
LVS的角色:
1 | DS:director server,即负载均衡器,根据一定的负载均衡算法将流量分发到后端的真实服务器上. |
LVS组成:
LVS 由2部分程序组成,包括ipvs和ipvsadm。
ipvs工作在内核空间,是真正生效实现调度的代码.
1 | ipvs基于netfilter框架,netfilter的架构就是在整个网络流程的若干位置放置一些检测点(HOOK). |
ipvsadm工作在用户空间,负责为ipvs内核框架编写规则, 它是一个工具,通过调用ipvs的接口去定义调度规则,定义虚拟服务(VS)。
LVS请求的流程
1 | 1、客户端(Client)访问请求发送到调度器(Director Server)。 |
下面我主要记录一下LVS调度的方式和原理。
LVS的调度
调度算法
调度算法也就是指负载均衡算法,注意LVS只负责负载均衡,不负责探活和保证RS的高可用。
静态算法
不考虑Real Server实时的活动连接和非活动连接
1 | rr:轮询 |
动态算法
ipvs默认的调度算法是下面的wlc
1 | lc:最少连接数调度(least-connection),IPVS表存储了所有活动的连接。LB会比较将连接请求发送到当前连接最少的RS. (active*256+inactive) |
调度方式
NAT方式
NAT(Network Address Translation),类似于防火墙的私有网络结构,Director Server作为所有服务器节点的网关,即作为客户端的访问入口,也是各节点回应客户端的访问出口,其外网地址作为整个群集的VIP地址,其内网地址与后端服务器Real Server在同一个物理网络,Real Server必须使用私有IP地址。
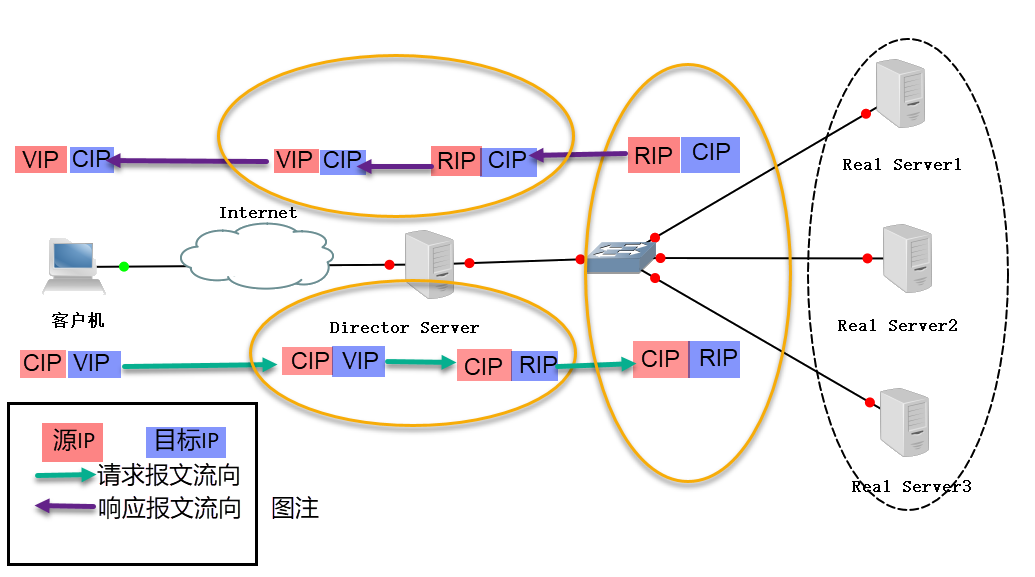
1 | 1. 参考上面LVS请求的流程,修改数据包的目标IP地址为后端服务器IP,重新封装数据包(源IP为CIP,目标IP为RIP),然后选路将数据包发送给Real Server。 |
由此可总结特点如下:
从上面第一点分析,DS修改了网络层的IP和传输层的端口,所以NAT支持端口映射,VIP的PORT可以不同于RS的PORT。
从上面第二点分析,为了让RS的响应经过DS,我们必须把RS的网关设置为DS。
从上面第三点分析,响应的过程DS修改源IP并转发数据包,所以DS必须开启IP-Forward.
1 | IP-Forward即当主机拥有多于一块的网卡时,其中一块收到数据包, |
从流程上看,NAT方式的数据进出都经过DS,DS容易成为性能瓶颈;RS和DS必须在同一个VLAN,即处于同一个局域网。
DR方式
DR(Direct Routing),Director Server作为群集的访问入口,但不作为网关使用,后端服务器池中的Real Server与Director Server在同一个物理网络中,发送给客户机的数据包不需要经过Director Server。即input经过DR,output不经过DR。为了响应对整个群集的访问,DS与RS都需要配置有VIP地址。
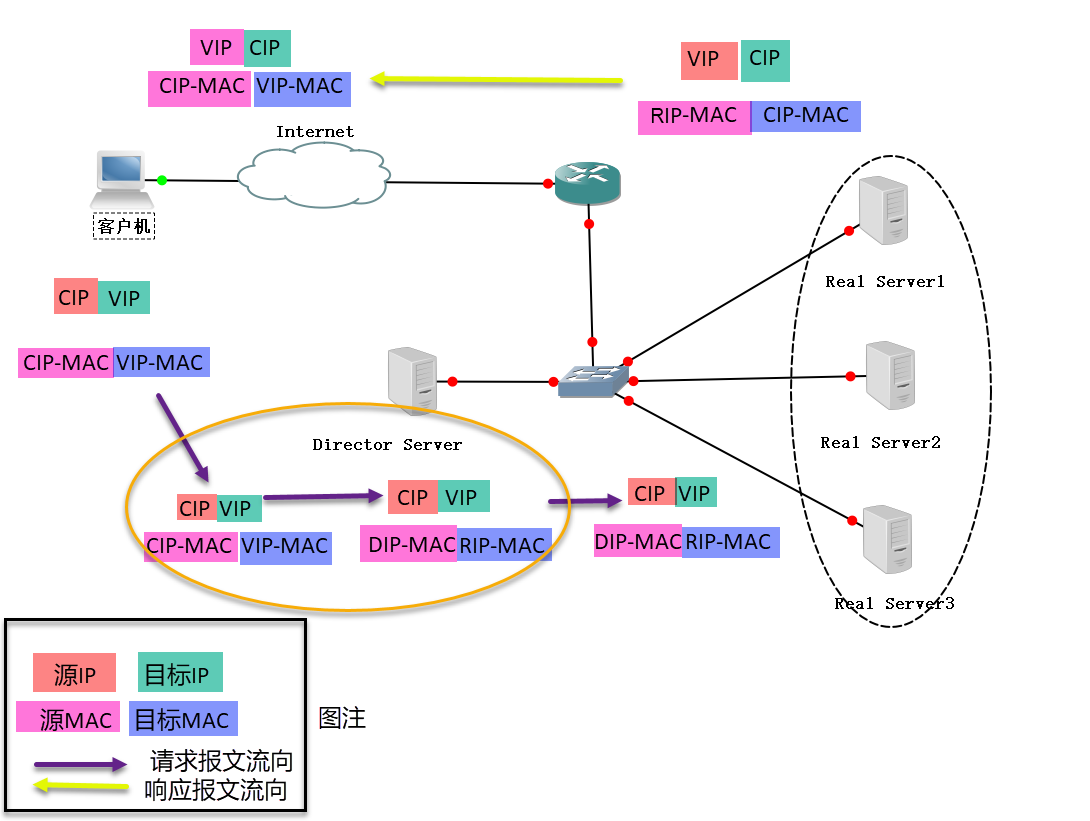
1 | 1. 参考上面LVS请求的流程,修改数据包的源MAC地址为DS的MAC,目标MAC地址为RS的MAC,重新封装数据包然后选路将数据包发送给Real Server。 |
由此可总结特点如下:
从上面第一点分析,DS只修改了数据链路层的MAC,没有修改传输层的数据,所以NAT不支持端口映射。
从上面第二点分析,DS没有修改IP,数据包的IP还是VIP,所以为了让RS认为数据包是发给他的,必须给RS绑定一个VIP,通常就绑定到lo上面去,所以RS的lo都需要绑定VIP。
同时DS必须能通过ARP请求查到RS的MAC,如果不在同一网段则会隔离arp,所以DS和RS必须在同一个VLAN。
此时网络中就同时存在DS和RS的多个IP为VIP的机器,所以这里需要抑制RS的arp响应,否则DS和RS就都会回应自己是VIP,造成混乱。所以设置arp_ignore=1或者2,见下面arp_ignore的解释。
再从上面第二点分析,RS响应数据包的源MAC是eth0,而源IP是VIP,但是如果这个mac和ip对让别的机器知道了,就存在DS_MAC-VIP和RS_ETH0_MAC-VIP映射,造成混乱。这里就需要设置arg_annouce=2,让响应的数据包的ARP查询中源IP使用eth0的IP,设置方法见下面的解释。
同时可知该模式下响应不经过DS,因此其性能会优于NAT方式。
同时可知DS不需要承担数据转发的工作,因此不需要开启Ip-Forward.
这里补充对ARP的设置方法:
1 | 我们知道仰制arp帧需要在server上执行以下命令,如下: |
arp_ignore的意义
1 | 0(默认) |
arp_annouce的意义
1 | arp_annouce用来设置当lo的数据包通过eth0发送ARP查询时(lo和eth0指的任意两个网卡),数据包的源ip是用lo的ip还是eth0的ip。 |
可以看到,DR方法虽然效率更高,但是RS的设置比较麻烦,要设置lo绑定VIP,还要设置arp_ignore和arp_annouce。
这里暂停一下,不知道你发现没有,NAT和DR两种方式,都存在一个严重的问题,DS和RS都必须在同一个网段,那异地部署怎么办呢?
所以后面列举一下解决跨网段问题的转发方式,TUN/FUNNNAT。NAT/DR/TUN/FULLNAT加在一起就是全部LVS的转发方式了。
TUN方式
我们回忆下,在DR方式下,DS只修改数据包中数据链路层的MAC信息,IP信息不修改。于是DS通过MAC来定位RS,由此限制了DS和RS要处于同一网段。
那么如果DS可以不通过MAC就可以定位到RS的话,也就不用限制RS和DS处于同一网段了。
而IP Tunnel正好可以解决这一问题。
1 | ip隧道简单解释一下,ip隧道可以理解为IP in IP, 即发送方在IP头的外部再包装一个IP头,接收方先解出第一层IP头,然后再按照正常流程处理剩下的的IP数据包。 |
有了ip tunnel技术,我们就可以把RS分布到不同的机房下,如下图
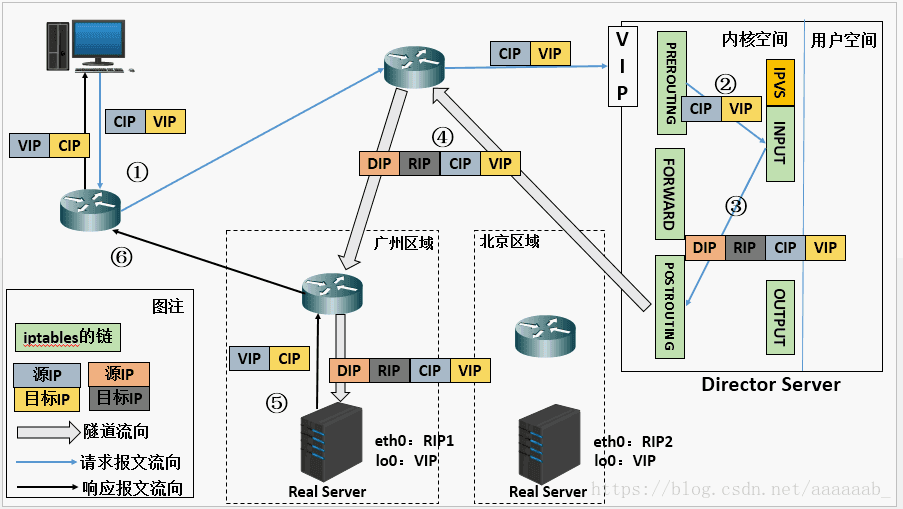
1 | 1. 参考上面LVS请求的流程,给数据包添加新的IP头,重新封装数据包然后选路将数据包发送给Real Server。 |
由此可总结特点如下:
从第一点分析,DS添加了IP头,但是不修改传输层数据,所以TUN不支持端口映射。
从第二点分析,只要IP可达,RS完全可以分布到不同的机房和网段。同时可知DS这里不需要两张网卡,所以也不需要开启IP-forward。
从第三点分析,RS需要绑定VIP到lo,同时这里没有提到arp抑制,那是因为tun方式下,DS和RS常不在同一网段,也就不会引起DS和RS的ARP混乱。一旦DS和RS部署在一个网段,那么跟DR一样,需要配置ARP抑制。对于同一网段下的RS之间也会引起ARP映射混乱,不过没什么影响。
注意tun方案下会存在MTU的问题,如果一个数据包已经达到了mtu的大小,ip隧道添加一个ip头之后,包的大小就会超过MTU。这个时候有两个方案来解决。
支持PMTUD协议
1 | 每个数据包都要封装一个新的20字节的IP头,如果LVS上收到的数据包就已经达到了Ethernet帧的最大值1514(MTU1500+帧头14),这时候封装层的IP头就无法加进去。 |
减小RS的MSS
1 | 可以通过减少RS侧的MSS值,比如调到1480。 |
TUN方式确实解决了RS的部署和扩展问题,但是DS的扩展问题还是无法解决,我们能做的顶多是对DS实行主备高可用,想要扩展DS还是没法做到。所以就有了FULLNAT方式。
FULLNAT方式
上面三种调度方法都只能适用于一定规模的集群,对于大企业的大规模集群,上面那几个都被DS的扩展能力约束住了。
FULLNAT是由淘宝最先实现的一种调度方式,重点解决DS的扩展能力,以及其他一些优化。目前业界的大厂都是基于这个方案来做的。
FULLNAT试图消除前面几个方案的不便之处:DR和NAT都需要在同一网段,TUN需要配置ipip模块。
下图是基于NAT的流程图做的修改:
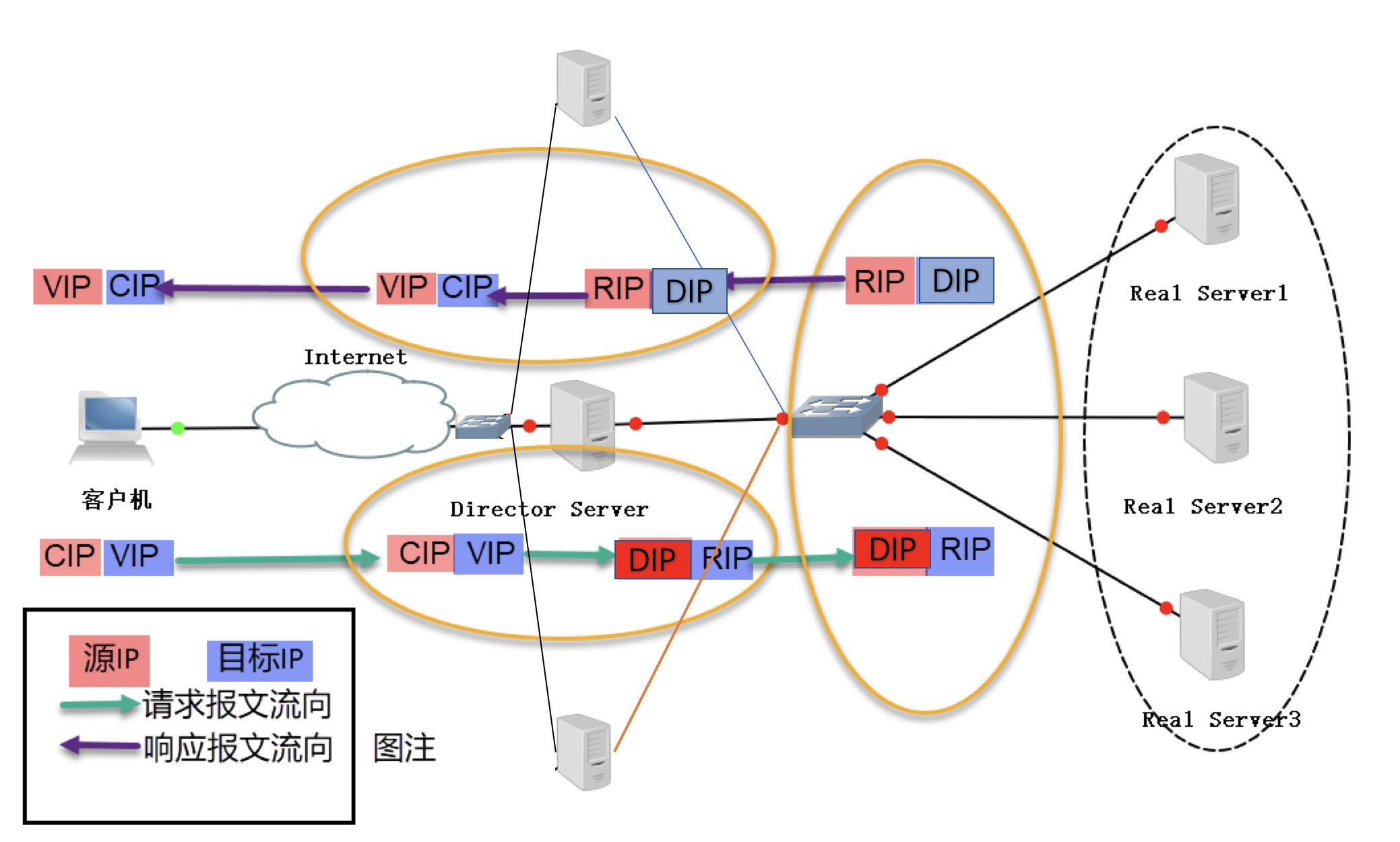
可以看到两个明显的差别,一个是DS进行了横向扩展,DS之前增加了一个交换机。一个是RS返回数据不是靠的配置默认网关,而是明确的把数据发往DS。流程如下:
1 | 1. DS前面的交换机选择一台DS,把请求发送到该DS。 |
由此可总结特点如下:
从第一点分析,可知需要一个让交换机选择DS的策略,答案就是OSPF。
1 | OSPF路由协议用于在单一自治系统内决策路由。 |
从第二点分析,DS按照常规流程修改ip和端口,所以支持端口映射。
从第三点分析,RS不需要配置默认网关,所以RS可以跨机房跨网段部署。
从第四点分析,返回数据需要进行转发,所以需要开启DS的ip_forward.
这个流程其实偏复杂了,因此带来了一些问题,比如
如何透传CIP
RS这时候是看不到CIP的,只能看到DS的IP,解决办法是DS发给RS的数据包中通过TCP option携带CIP,RS通过toa模块hook获取ip的函数,使返回TCP option中的IP。
DS动态增减
DS在增减节点的时候,会引起路由改变,某个连接的数据会被发送到不存在该连接session信息的DS上,造成异常,结果就是该连接下线或者重连。解决方法是使用支持一致性hash的交换机(支持的交换机较少所以不太考虑),或者使用session同步,即DS之间互相同步session信息,每个DS都保留一份全量的session表。这样DS节点下线时别的DS也有session信息,所以连接不受影响。新节点上线时,则首先全量同步session信息再把自己加到交换机的下游去。
RS动态增减
RS在增减节点的时候,可能导致某个客户端新建的连接落不到同一个RS上,这可能会影响某些业务。所以这就要求DS使用一致性算法来调度客户端的连接,同时要求每个DS拥有同样的调度算法。
k8s ipvs
k8s在启用ipvs的proxy-mode:"ipvs"之后,会作出如下操作:
启动ipvs后, k8s会在每一台主机上创建一个kube-ipvs0的虚拟网卡。创造一个svc后,相应的clusterip和externalip会绑定到kube-ipvs0上,随后这个主机作为DS,而svc下的ep作为rs挂到vip下。
那么k8s用了哪一种转发模式呢?
首先为了支持端口转发,只能选择NAT和FULLNAT,但是NAT要求机器都在同一个网段,所以NAT不可取,剩下的只能选择FULLNAT。
1 | 1. k8s集群内主机通过clusterip访问svc,或者外部通过externalip访问svc把请求路由到这个机器,也就是请求达到这个VIP对应的DS(多个中的一个)。 |
可以看到跟fullnat的流程是一样的,只不过请求达到ds的方式不同,之前我们讲到是通过OSPF,这里则不同。如果是走clusterip那么直接走本机的kube-ipvs0,如果走externalip那么是靠cloud供应商的负载均衡,把请求转发到主机上。
metalLB的负载均衡
metalLB可以在裸集群上实现externalip功能,代替云供应商的负载均衡。有两种方式把externalip引到主机,一个是通过内部协议选择主机响应arp请求;一个是通过bgp协议加上ECMP特性。
内部协议没有使用Keepalived采用的VRRP,而是使用了memberlist协议,memberlist协议是gossip协议的变种。
bgp协议则要配合路由器支持ECMP特性,主机通过BGP连接上路由器,路由器通过ECMP选择主机。
同样这个方案需要注意上面fullnet遇到的问题,不然数据包会乱走,走的路线不同一方面会导致数据乱序,另一方面数据包到了不同k8s主机后,可能转发到不同pod导致连接异常。
总结
| 调度方式 | 端口映射 | ip转发 | 性能 | 部署 | 扩展性 | 其他注意点 |
|---|---|---|---|---|---|---|
| NAT | 支持 | 需要 | 较低 | 同网段 | 一般 | 配默认网关 |
| DR | 不支持 | 不需要 | 最高 | 同网段 | 一般 | arp抑制,绑定VIP |
| TUN | 不支持 | 不需要 | 较高 | 跨网段 | 较好 | 绑定VIP; ipip模块;MSS调整 |
| FULLNAT | 支持 | 需要 | 最低 | 跨网段 | 最好 | OSPF&ECMP;CIP透传;session同步 |
参考资料
[1]LVS负载均衡集群架设
[2]LVS调度方法
[3]LVS负载均衡之LVS-NAT与LVS-DR模式原理详解
[4]LVS负载均衡之工作原理说明(原理篇)
[5]LVS-Ip Tunnel模式应用
[6]ip_forward与路由转发
[7]LVS-Ip Tunnel模式应用
[8]美团点评高性能四层负载均衡
[9]METALLB IN LAYER 2 MODE
[10]METALLB IN BGP MODE
[11]Github memberlist