golang scheduler
Go调度器
我们知道Go里面有成千上万coroutine需要调度执行,而这里面起关键作用的就是Go的调度器,那么Go的调度器在哪里呢?因为我们写Go代码的时候从未显式创建过调度器实例。为了了解调度器,我们先来了解下Go的运行时(Runtime)。
为什么要有Runtime
开销上
我们知道操作系统是可以调度线程的,那么我们可不可以直接让操作系统调用go的线程呢。
POSIX线程(POSIX是线程标准,定义了创建和操纵线程的一套API)通常是在已有的进程模型中增加的逻辑扩展,所以线程控制和进程控制很相似。线程也有自己的信号掩码(signal mask), 线程也可以设置CPU亲和性(CPU affinity),也可以放进cgroups中进行资源管理。假如goroutines(go的执行单元)对应线程的话,使用这些特性对线程进行控制管理就增加了开销,因为go程序运行goroutines(go的执行单元)不需要这些特性。这类消耗在goroutine达到比如10,0000个的时候就会很大。所以go需要有个运行时在调度goroutines而不是只是让操作系统调度线程。
垃圾回收上
go包含垃圾回收(GC)的特性,在垃圾回收的时候所有goroutines必须处于暂停的状态,这样go的内存才会处于一种一致的状态. 所以我们必须等待所有线程处于内存一致的状态才能进行垃圾回收。
在没有调度器的时候,线程调度是随操作系统的意的,你不得不试图去等待所有的已经暂停和还没暂停的线程,而且不知道等多久, 暂停后如何让他们保持暂停直到gc结束,也是一个难题。
在有调度器的时候,调度器可以决定只在内存一致的时候才发起调度(即只要有活跃的线程就不执行新的任务),因此当需要执行gc的时候,调度器便决定只在内存一致的时候才发起调度,所以所有线程都无法再次活跃,调度器只需要等待当前活跃的线程暂停即可。后面还会讲到调度器还想办法避免一个活跃的线程长时间不停下来。
需要调度器自然就需要运行调度器的运行时。
基于这两个原因, golang需要一个运行时(Runtime).
或者简单的讲,要想做协程线程调度就要有运行时。要想做垃圾回收就要有运行时。
什么是Runtime
上面可以分析出Runtime所担任的职责:goroutines调度,垃圾回收,当然还提供goroutines执行的环境。
所以这也相当于简要解释了什么是Runtime。
go的可执行程序可以分成两个层:用户代码和运行时,运行时提供接口函数供用户代码调用,用来管理goroutines,channels和其他一些内置抽象结构。用户代码对操作系统API的任何调用都会被运行时层截取,以方便调度和垃圾回收。分层如如些:
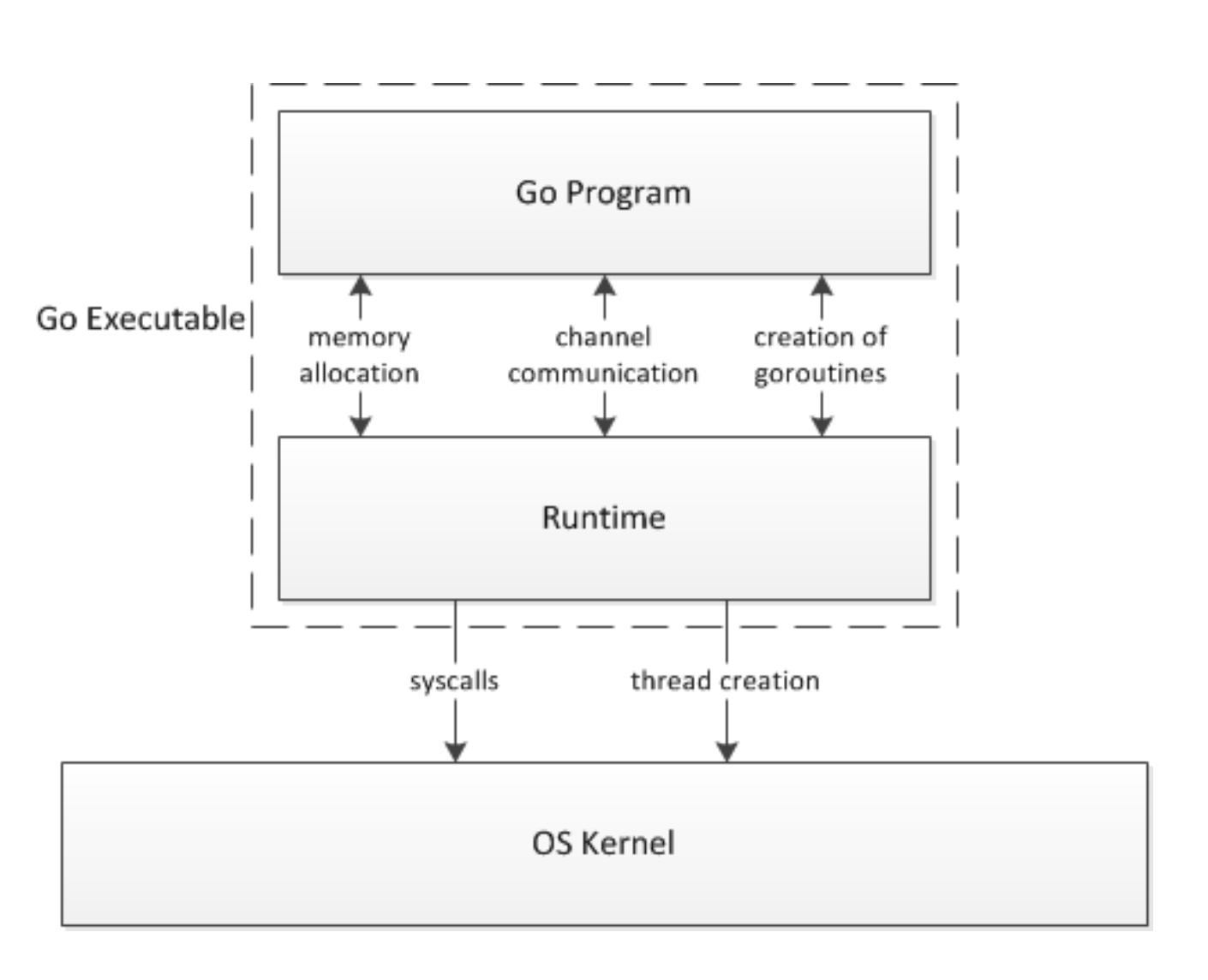
图片来自 Analysis of the Go runtime scheduler
初代调度器
Go的调度程序是Go运行时的一个更重要的方面。运行时会跟踪每个Goroutine,并将安排它们在线程池中运行。goroutines与线程分离(解耦不强绑定),但运行于线程之上。如何有效地将goroutine调度到线程上对于go程序的高性能至关重要。
Goroutines的背后逻辑是:它们能够同时运行,与线程类似,但相比之下非常轻量。因此,程序运行时,Goroutines的个数应该是远大于线程的个数的。
同时多线程在程序中是很有必要的,因为当goroutine调用了一个阻塞的系统调用,比如sleep,那么运行这个goroutine的线程就会被阻塞,那么这时运行时至少应该再创建一个线程来运行别的没有阻塞的goroutine。线程这里可以创建不止一个,可以按需不断地创建,而活跃的线程(处于非阻塞状态的线程)的最大个数存储在变量GOMAXPROCS中。
go运行时使用3个结构来跟踪所有成员来支持调度器的工作。
G:
一个G代表一个goroutine,包含当前栈,当前状态和函数体。
1 | struct G |
M:
一个M代表一个线程,包含全局G队列,当前G,内存等。
1 | struct M |
SCHED:
SCHED是全局单例,用来跟踪G队列和M队列,和维护其他一些信息。
1 | struct Sched { |
运行时刚启动时会启动一些G,其中一个负责垃圾回收,其中一个负责调度,其中一个负责用户的入口函数。一开始运行时只有一个M被创建,随后,用户层面的更多G被创建,然后更多的M被创建出来执行更多的G。同时最多同时支持GOMAXPROCS个活跃的线程。
M代表一个线程,M需要从全局G队列中取出一个G并且执行G对应的代码,如果G代码执行阻塞的系统调用,那么会首先从空闲的M队列中取出一个M唤醒,随后执行阻塞调用,陷入阻塞。这么做是因为线程阻塞后,活跃的线程数肯定就小于GOMAXPROCS了,这时我们就可以增加一个活跃的线程以防止当前有G在等在M。
造成阻塞的都是系统调用,在调用返回之前,线程会一直阻塞。但是注意,M不会在channel的操作中阻塞,这是因为操作系统并不知道channel,channel的所有的操作都是有运行时来处理的。所以如果goroutine执行了channel操作,这时goroutine可能会需要阻塞,但是这个阻塞不是操作系统带来的阻塞,因此M并不需要一起阻塞。这种场景下,这个G会被标记为waiting,然后原来执行这个G的M会继续去执行别的G。waiting的G在channel操作完成后会设为runable状态,并把自己放回到原来那个q的队列下,等待空闲的M来执行,不一定是先前那个M了。为了完成g的唤醒,waitting的这个g必然会在wating前先找个地方某个字段某个数组保存。
初代的问题
初代的调度器相对简单,所以也存在一定的问题,当然初代调度器的目的不是要马上做到成熟,只是在有限的时间内做出一个还可以的版本。
Dmitry Vyukov(新调度器的作者)写的一个论文列举了老调度器存在的问题:
以下来自Scalable Go Scheduler Design Doc
第一个问题是全局锁,无论是修改M还是G的队列还是其他SCHED结构的相关字段,都需要获取这个全局锁,当遇到高吞吐高并发的程序的时候,这个设计会导致调度器的性能问题。
第二个是当前有很多M之间传递G的情况,比如新建的G会被被放到全局队列,而不是在M本地执行,这导致了不必要的开销和延迟,应该优先在创建G的M上执行就可以了。
第三个问题是每一个M现在都持有一个内存,包括了阻塞状态的M也是持有的。Active状态的M跟总的M个数之比可以达到1:100。这就导致了过多的内存消耗,以及较差的数据局部性。数据局部性怎么理解呢?数据局部性这里是指G当前在M运行后对M的内存进行了预热,后面如果再次调度到同一个M那么可以加速访问,可想而知,因为现在G调度到同一个M的概率不高,所以数据局部性不好。
第四个是M持续的阻塞和唤醒带来的开销。比如M找不到G(目的是一有runable的G就执行),此时M就会进入频繁阻塞/唤醒来进行检查的逻辑,以便及时发现新的G来执行。
新调度器
调度器细节
Dmitry Vyukov的方案是引入一个结构P,用来模拟处理器,M依旧表示操作系统线程,G依旧表示一个goroutine。
GOMAXPROCS用来控制P的个数,同时P作为M执行G代码时的必需资源。
新的P结构会带走原来的M和SCHED结构中的一些属性,比如MCache从M移到了P,而G队列也被分成两类,SCHED结构保留全局G队列,同时每个P中都会有一个本地的G队列。
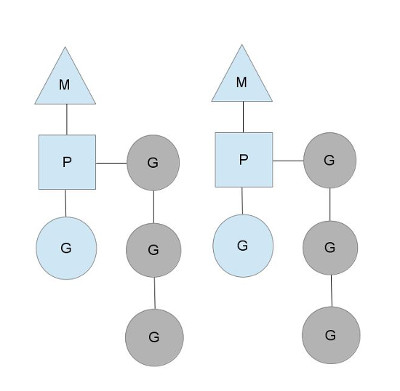
图片来自go-scheduler
P的本地队列可以解决旧调度器中单一全局锁的问题。注意P的本地G队列还是可能面临一个并发访问的场景,比如下面讲到的窃取算法。为了避免加锁,这里P的本地队列是一个LockFree的队列,窃取G时使用CAS原子操作来完成。关于LockFree和CAS的知识参见Lock-Free。
而P的MCache也就意味着不必为每一个M都配备一块内存,避免了过多的内存消耗。
当一个新的G被创建的时候,G被放到当前M所关联的P的本地队列结尾,这样G虽然不是立即执行,但最终会得到执行。
当P执行系统调用即将阻塞时,M会释放P,并进入阻塞,直到系统调用返回时,M会尝试获取空闲的P,有的话继续执行,没有就把G会放到全局G,而M会进入空闲的M队列。
由于每个P都有G队列,那么当一个P的G队列执行完了的时候,另一个P却可能堆积了很多G,所以新的调度器有个G的调度算法,一般都叫做窃取算法(stealing algorithm)。
当一个P执行完本地所有的G之后,会尝试随机挑选一个受害者P,从它的G队列中窃取一半的G。当尝试若干次窃取都失败之后,会从全局G队列中获取G。那么一次从全局队列取多少个呢,取 [当前个数/GOMAXPROCS]个(忽略其他一些限值检查)。所以可以看到这个全局队列使用的频率很低,虽然也是全局锁但是不至于影响性能。当然光窃取失败时获取是不够的可能会导致全局队列饥饿。P的算法中还会每个N轮调度之后就去全局队列拿一个G。那么全局队列的G又是谁放进去的呢?是在新建G时P的本地G队列放不下的时候会放半数G到全局队列去,阻塞的系统调用返回时找不到空闲P也会放到全局队列。
完整的过程其实比较繁琐,取g的完整顺序为: local->global->netpoll->steal->global->netpoll
在窃取到的G中,有一些G是标记了它绑定的M的,遇到这类G的话,当前M就会检查这个绑定的M是否是空闲状态,如果是空闲的话(不空闲就有问题了,这个M是专门执行这个G的不会执行别的G)就会把这个M唤醒,然后把P和G交给它去执行,自己则进入阻塞状态。这部分逻辑是实现协程和线程一一绑定的关系,参见LockOSThread。
同时新调度器中引入了线程自旋,自旋有好处有坏处,好处是避免线程被阻塞陷入内核,坏处是自旋属于空转,浪费CPU。只能说适度使用自旋是可以带来好处的。新方案在两个地方引入自旋:
1,M找不到P(目的是一有P释放就结合)
2,M找到了P但找不到G(目的是一有runable的G就执行)
由于P最多只有GOMAXPROCS,所以自旋的M最多只允许GOMAXPROCS个,多了就没有意义了。同时当有类型1的自旋M存在时,类型2的自旋M就不阻塞,阻塞会释放P,一释放P就马上被类型1的自旋M抢走了,没必要。
在新G被创建,M进入系统调用,M从空闲被激活这三种状态变化前,调度器会确保至少有一个自旋M存在,除非没有空闲的P。
我们来分析下,当新G创建,如果有可用P,就意味着新G可以被立即执行,即便不在同一个P也无妨,所以我们保留一个自旋的M(这时应该不存在类型1的自旋只有类型2的自旋)就可以保证新G很快被运行。当M进入系统调用,意味着M不知道何时可以醒来,那么M对应的P中剩下的G就得有新的M来执行,所以我们保留一个自旋的M来执行剩下的G(这时应该不存在类型2的自旋只有类型1的自旋)。如果M从空闲变成活跃,意味着可能一个处于自旋状态的M进入工作状态了,这时要检查并确保还有一个自旋M存在,以防还有G或者还有P空着的。
现在来看下面这个图应该在理解上就没有大问题了:
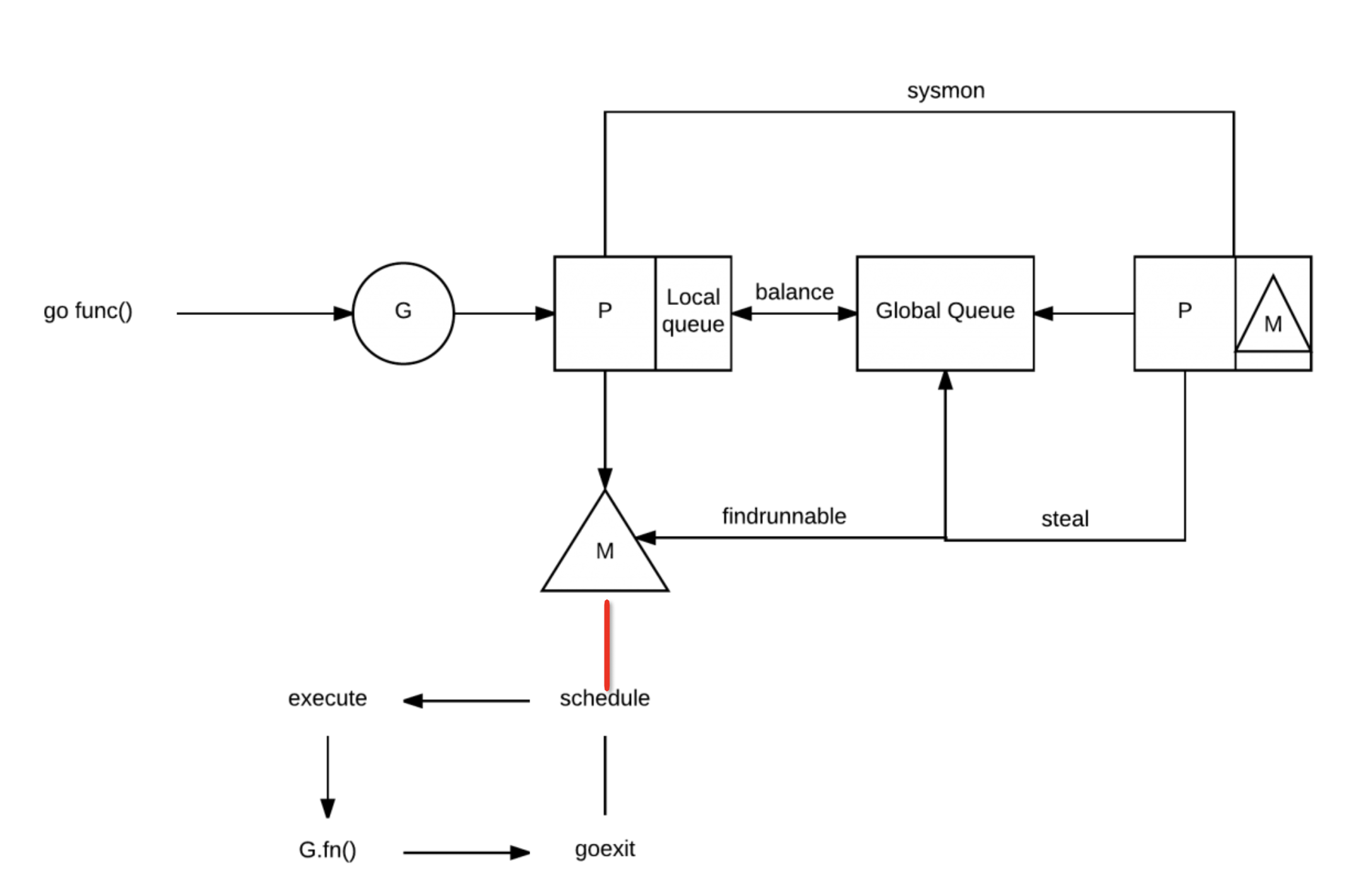
图片来自go-scheduler
问题总结
到这里,老调度器中的问题已经一一被解决了。我们来一一回顾下:
全局锁的问题
G被分成全局G队列和P的本地G队列,全局G队列依旧是全局锁,但是使用场景明显很少,P本地队列使用无锁队列,使用原子操作来面对可能的并发场景。
G传递带来开销的问题
G创建时就在P的本地队列,可以避免在G之间传递(窃取除外); 当G开始执行了,系统调用返回后M会尝试获取可用P,获取到了的话可以避免在M之间传递。
内存消耗问题
内存MCache只存在P结构中,P最多只有GOMAXPROCS个,远小于M的个数,所以内存没有过多的消耗。
数据局部性问题
新建的G放在本地队列,所以G对P的数据局部性好;系统调用后尝试获取可用P并执行,而且优先获取调用阻塞前的P,所以G对M数据局部性好,G对P的数据局部性也好;由于总的内存数目最多只有GOMAXPROCS而不是M的个数了,因此G调度到拥有同一块内存的执行单元的概率也就变大了,数据局部性也就变好了。
数据局部性还可以更好的,比如M选择空闲P时可以优先选择上一次绑定过的P。
频繁阻塞和唤醒
通过引入自旋,保证任何时候都有处于等待状态的自旋M,避免在等待可用的P和G时频繁的阻塞和唤醒。
Go程序的启动过程
整个程序始于一段汇编:
1 | // _rt0_amd64 is common startup code for most amd64 systems when using |
而在随后的runtime·rt0_go(也是汇编程序)中,go一共做了这么几件事:
绑定m0和g0
m0和g0是什么呢,m0就是程序的主线程,程序启动必然会拥有一个主线程,这个就是m0.
每一个m结构中会包含两个主要的g:
1 | type m struct { |
可以看到m中的g0负责调度,curg是具体的任务g。因此这里的g0也就是m0的g0。而m0的curg现在还是空的。
创建p,绑定m0和p0
这里并不是去初始化g0,而是创建出了所需的p,p的数目优先取环境变量GOMAXPROCS,否则默认是cpu核数。随后把第一个p(便于理解可以叫它p0)与m0进行绑定,这样m0就有他自己的p了,就有条件执行后续的任务g了。
新建任务g到p0本地队列
这里m0的g0会执行调度任务(runtime.newproc),创建一个g,g指向runtime.main()(还不是我们main包中的main),并放到p的本地队列。这样m0就已经同时具有了任务g和p,什么条件都具备了。
执行统一的调度任务
调度器实现中有个同一个调度器入口,叫mstart(),这个实现中会去获取一个空闲的p(如果没有),然后执行schedule(), schedule中就会去不停的寻找可用的g来执行。这里其实初始工作已经全部完成并且把调度器启动起来了。后面可以不用管了,可以自动跑起来了。
持续调度
由于前一个步骤已经在p0中插入了一个指向runtime.main的g,所以显然之后第一个跑起来的任务g就是runtime.main。
runtime.main的工作包括:启动sysmon线程(这个线程游离在调度器之外,不受调度器管理,下面再讲);启动gc协程;执行init,这个就是统一执行我们代码中书写的各种init函数;执行main函数,这个就是我们main包中的main,可以看到,到这里我们的函数入口才终于被执行到了。
再后面就是前面讲过的GMP模型的工作过程了,main会创建g,g被放入p,并且触发m的创建,如此循环往复。
Sysmon线程
我们前面遗留了一些没有解释的工作流程,一个是调度器如何抢占长时间不返回的g,一个是sysmon是做什么的.这里可以一起解释了。因为调度器就是通过sysmon来进行抢占的。
sysmon也叫监控线程,它无需P也可以运行,他是一个死循环,每20us~10ms循环一次,循环完一次就sleep一会,为什么会是一个变动的周期呢,主要是避免空转,如果每次循环都没什么需要做的事,那么sleep的时间就会加大。
sysmon主要做下面几个事:
-
释放闲置超过5分钟的span物理内存;
-
如果超过2分钟没有垃圾回收,强制执行;
-
将长时间未处理的netpoll结果添加到全局G队列;
-
向长时间运行的G任务发出抢占调度;
-
收回因syscall长时间阻塞的P;
那么抢占就是发生在第4点。
当sysmon发现一个p一直处于running状态超过了10ms,那么就给这个g设置一个标志位,随后等到这个g调用新函数的时候,会检查到这个标志位,并且重新进行调度,不让这个g继续执行。
不过并不是设置了标志位就一定会被调度,这里有两个条件,一个是g必须调用函数,否则如果是一个简单的死循环是无法抢占成功的;另一个条件是即使调用了新函数,如果新函数所需的栈空间很少,那么也不会触发检查这个标志位,只有调用了会触发栈空间检查(所需栈大于128字节,详见知乎回答)的函数,才会抢占成功。
第5点是什么意思呢,我们知道g中调用系统调用后会解绑p,然后m和g进入阻塞,而p此时的状态就是syscall,表明这个p的g正在syscall中,这时的p是不能被调度给别的m的。如果在短时间内阻塞的m就唤醒了,那么m会优先来重新获取这个p,能获取到就继续绑回去,这样有利于数据的局部性。
但是当m较长时间没有唤醒的话,p继续等的成本就有点大了,这个时候sysmon就会吧他设为idle,重新调度给需要的M。这个时间界限是10ms,超过10ms就会被sysmon回收用于调度。
go的协程模型
这部分跟调度器关系不大,主要是补充一个知识点。
golang的goroutines是基于CSP(Communicating Sequential Processes)理论模型来设计的。
CSP主要是指两个独立的Process,通过共享Channel来交互。并发模型除了CSP另外还有Actors模型。
CSP和Actors简介
CSP模型就是coroutine+channel的模式。
coroutine之间通信是通过channel实现的,coroutine之间可以共享channel。
比如golang就是基于CSP实现的。
Actors模型就是coroutine+message的模式。
coroutine之间通信是通过message实现的,message是明确的发送给某个coroutine的。
比如erlang就是基于Actors实现的。
CSP和Actors的区别
同步异步
CSP的通信机制通常是同步的,任务被推进channel后立即被对端收到并执行,如果对端正忙,则发送者就阻塞无法推送该任务,golang对channel进行了修改,支持缓存任务,可以缓存多个任务等待执行,避免发送者阻塞。
Actors的通信机制通常是异步的,消息发送时发送者不会阻塞,接收者也不一定马上收到,收到也不一定马上执行。erlang中的actor角色非常广泛,可以是同个runtime下的,也可以是runtime间的,甚至可以是机器间的。
匿名性
CSP中的channel通常是匿名的,任务放进channel后你并不知道对端是谁在接收。
Actors中的message通常有确定目标,你需要确切的知道对方的地址(ID/NAME/PORT等)才能将信息发送出去。
耦合性
CSP中channel是共享的,可以多个生产者可多个消费者公用,生产者消费者之间不强关联。
Actors中你必须知道对方的地址(ID/NAME/PORT等),这导致生产者和消费者之间发生耦合,对方actor是不可替换的。
容错
CSP没有定义容错方面的内容,所以开发者需要自己处理channel接收和发送的错误,这些错误处理逻辑可能会到处都是。
Actors支持容错,你可以定义错误的类型,错误处理方式,错误的级别等。
参考资料
Analysis of the Go runtime scheduler