SOA框架iceoryx原理解析
SOA框架iceoryx原理解析
简介
这篇文章,会介绍一个SOA框架,框架提供高效的通信能力。这个是他的logo,很漂亮,会让你忍不住想,这大概是个很酷的框架。
![]()
在我之前的一篇微服务的文章中曾经总结了微服务跟SOA的差异点和相同点,总结的结论如下:
1 | 差异可以归纳为: |
基于这个总结,如果我们现在要写一套SOA服务框架,我们可以推导出这个框架的哪些特性呢?
从第一条中我们可以看出这套框架将是一个企业级别的框架,他不像微服务那样可以给每个服务灵活和独立的特性,SOA框架一旦推广使用,他就是企业级别的。
从第二条中我们可以看出,这个框架承担着异构集成的职责,异构集成简单讲就是适配加标准化公开这两点。展开来讲的话就是适配现有系统中的的专用数据格式、协议、传输机制,并使用标准化的机制将这些公开为服务。
从第三点上我们可以看出,这个框架所公开的服务,他们不一定像微服务那样一个服务与一个服务之间是网络隔离的,他们有可能是位于同一个主机上的,换句话说SOA的服务与服务之间可以网络隔离也可以网络不隔理。
这里面第一点可以认为是第二点的一个顺其自然的结果,由于各个服务都采用标准化的方式公开,那采用同一套框架是顺理成章的。所以下面我就只关注第二点和第三点。
这次要对其分析的这个框架叫iceoryx中文叫冰羚(其实就是对ice-oryx的翻译)。他是一个在特定领域(至少在智驾领域)很有名的SOA通信框架,在SOA特性的第二点和第三点特性中他都有很典型的体现,如下:
特性
标准化服务
为了做到第二点标准化的服务公开,iceoryx首先要求每个服务提供服务描述信息,用来唯一标志服务网络中的一个服务;
其次规定了专用数据格式,必须使用用户预定义的结构体(注意iceoryx没有规定使用IDL,IDL是在DDS等别的框架中的要求),或者无结构(也就是二进制流),用户想要传递自己已有的结构,需要在收发前后做数据结构的转换和赋值,这点在各类通信框架中到并不特殊;
再次,在传输机制上,iceoryx封装了较为复杂的消息编排和消息路由机制,确保消息是按照各异构服务提供方和消费方的要求做了保持或者丢弃,以及按需路由到了各个异构服务。要知道微服务是不做消息编排和路由的,这个也是SOA框架复杂麻烦的地方。即便只有一个服务需要这个特性,作为公司级的框架,你就不得不提供这个特性。
同主机通信
为了做到第三点对同一主机上的不同服务进行通信,iceoryx直接把自己瞄准在了这个细分领域,专注于提供同一主机上的不同服务之间的通信,他没有提供对不同主机上的服务的通信能力,因此在实践上,往往是跟其他框架整合使用。由于限定在同一主机上,他可以提供远高于主机之间的通信吞吐和远低于主机之间的通信延迟。
进程模型
我们已经知道iceoryx具有提供标准化服务的能力以及高性能同主机通信的能力,接下来我们首先来整体上大概的了解下iceoryx是如何工作的,先来看iceoryx的进程模型。
进程模型
接下来首先来看一下iceoryx运行时候的进程模型:
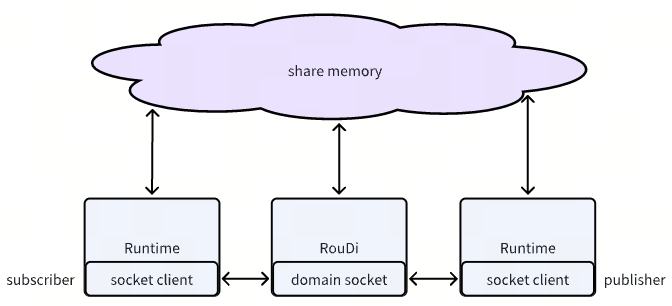
整个进程模型,包括3类角色,一个角色是RouDi,是一个中心进程节点,类似于Daemon进程,本身不属于业务进程,只是提供服务支持。RouDi的意思就是Route & Discovery,路由和发现,用来做消息路由和服务发现。
一个角色是Runtime,Runtime被集成到各个业务进程中,给进程提供服务集成的能力,根据使用方式不同,有的进程变成publisher,有的变成subscriber,有的既是publisher又是subscriber。
第三个角色是share memory,本身被RouDi创建和销毁,但被publisher和subscriber同时使用,被用来作为高效的数据传递介质。是其高性能的关键所在。
RouDi和Runtime之间通过domain socket(运行在Linux系统的话)通信,RouDi作为server,Runtime作为client。
接下来我们分别展开来看一下内部的交互以及RouDi和Runtime内部原理。
交互
roudi与runtime的交互过程,首先是roudi要先启动,如果runtime先启动,会等待若干秒,等待roudi启动,等不到就退出。
1 | 2024-06-29 16:32:03.011 [Warning]: RouDi not found - waiting ... |
所以所有的交互过程都是基于roudi已经启动成功的情况,暂不考虑roudi晚启动的异常情况。
交互总共包括以下几个指令,REG、CREATE_PUBLISHER、CREATE_SUBSCRIBER、CREATE_CLIENT,CREATE_SERVER、CREATE_CONDITION_VARIABLE、CREATE_INTERFACE、PREPARE_APP_TERMINATION、TERMINATION,如下面的代码所示, roudi收到对应的命令后会进入对应的命令处理逻辑。
1 | void RouDi::processMessage(const runtime::IpcMessage& message, |
REG 命令
REG命令是用来告诉roudi我runtime启动了,我的名字叫xx,我的其他信息是xxx,请记录。如果原先存在同名的runtime会在此时信息被更新。每个runtime因此必须有独一无二的name。
CREATE_PUBLISHER 命令
CREATE_PUBLISHER命令是告诉roudi,我要在xx这个runtime下创建一个publisher。roudi于是分配一片内存给这个publisher,这片内存是在专为publisher们准备的相同大小内存块的内存池中选取的一个,随后把这个内存的地址回复给runtime,这个地址本质上是一个offset值,不是一个真正的内存地址,因为roudi和runtime在不同进程,大家各自有各自的内存虚地址,我给你一个虚地址过去没有什么意义。在回复地址给到runtime之前,roudi还会同时做一个服务发现的工作,他会遍历当前已经存在的subscribers,把其中topic跟你这个publisher相同的subscriber选出来,这些subscriber,每一个也都绑定了一段专属的内存块,这些选出来的subscriber对应的内存块地址会被填入到publisher的专属内存地址中,一个存放subscriber信息的队列中。这样就完成了一个初始的服务发现的工作,publisher能够成功拿到当前有哪些关注我这个topic的subscribers。runtime拿到roudi的回复,就可以做后续的消息发布工作了。下面的代码反应了这个过程:
1 | expected<PublisherPortRouDiType::MemberType_t*, PortPoolError> |
下面的图则描述了这个过程。
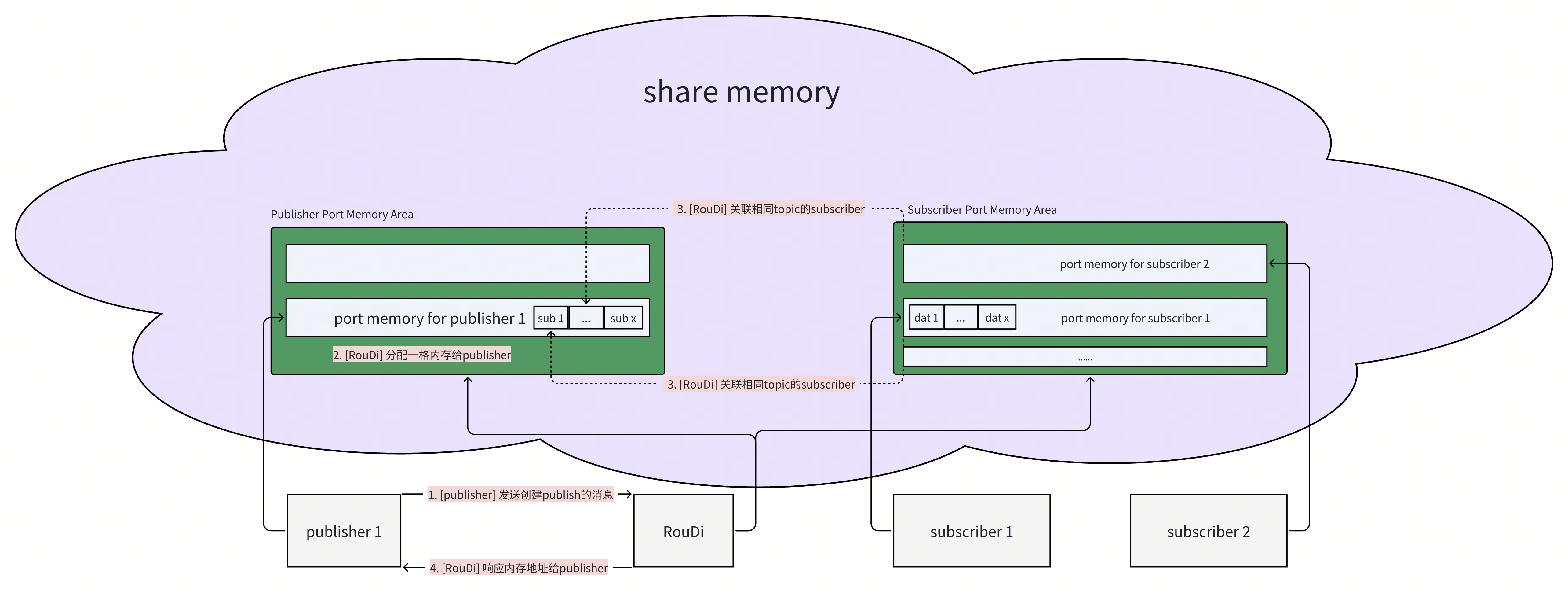
(右键-在新标签页中打开图片,可以看得更清晰)
CREATE_SUBSCRIBER 命令
CREATE_SUBSCRIBER命令同 CREATE_PUBLISHER类似的,roudi先是分配一段内存给这个subscriber,然后遍历全部的publisher,把这段内存地址的信息塞到相同topic的publisher的对应结构中去,如此完成初始的服务发现机制,然后把这段内存地址响应给subscriber,后续subscriber就可以根据这个信息去读取对应的数据。上图中在subscriber1的内存区域中有一个dat数组,就是存放publisher发过来的数据的。另外熟悉共享内存数据传递的同学应该知道,数据放在指定位置后,还得去做通知唤醒,告诉对方有新数据。不过呢 CREATE_SUBSCRIBER这个命令不负责这件事,但又做了部分的工作。当RouDi把subscriber的内存信息塞到publisher的对应结构中时,随同一起塞入的还有一个指针,指向通知器,只不过这个时候这个指针是空指针,也就是压根不会做通知。不做通知的话subscriber怎么读消息的,答案是轮询,这个场景也是合理的,轮询在适当场景下有更佳的性能。
1 | template <typename ChunkQueueDataProperties, typename LockingPolicy> |
CREATE_CONDITION_VARIABLE 命令
CREATE_CONDITION_VARIABLE命令的作用就是创建一个通知器,当用户代码中创建一个Listener, 他就会发送 CREATE_CONDITION_VARIABLE的命令,然后在用户代码中调用listener的attachEvent函数,完成subscriber与通知器的绑定,上面 CREATE_SUBSCRIBER命令介绍中提到的通知器指针,就会在这个时候被赋值,这样每次subscriber有新数据到来就会通知用户指定的回调。
1 | listener |
具体一点讲,listener对象中包含了roudi新创建的ConditionVariableData,ConditionVariableData中则包含了一个semaphore, 随后,listener会启动一个线程,线程会操作semaphore.wait(),进行等待。ConditionVariableData是被roudi创建的,pub和sub两侧都能拿到的,那么在数据传递后,pub端会随即操作semaphore.post(), 于是listener这边wait的线程就会唤醒并执行回调。ConditionVariableData在设计上支持多种事件的,因此里面有个数组,可以对应不同的事件,数组某个下标被设置上,就表示对应的事件发生,就执行对应的回调。ConditionVariableData这个类的定义可以看出这种设计。
1 | struct ConditionVariableData |
还原整个过程可以看下图:
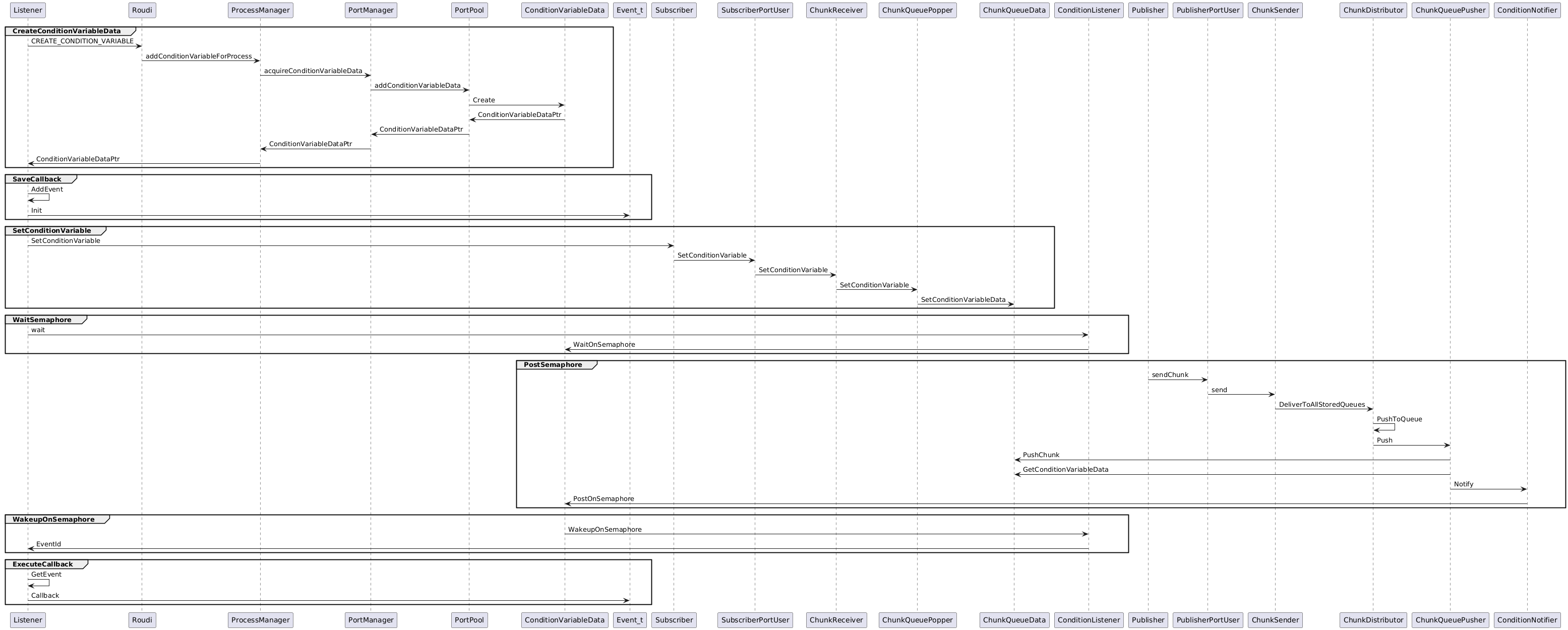
(右键-在新标签页中打开图片,可以看得更清晰)
1 | @startuml |
再补一个关系图,下面这个图是来自仓库中官方的一个图(doc/design/listener.md)。
1 | +---------------------------+ |
这个图中可以看出listener持有ConditionListener,listener正是通过ConditionListener实现的semaphore.wait(), 而ConditionVariableData、ConditionListener、Listener之间的关系则是1:1:1的关系。
另一部分ConditionNotifier是用来完成semaphore.post()操作的,因此ConditionNotifier可以构造多次执行多次,是1:n的关系。而原图中剩下的部分似乎是内容过期,已经不对了,我移除了,并 补上了Event_t部分。
TERMINATION 命令
TERMINATION命令发生在Runtime进程退出的时候,RouDi收到后会做一些清理操作,包括从订阅关系中移除这个进程,以及从进程列表中移除这个进程。如果Runtime进程异常退出,没来得及发送这个命令,那么这些清理操作将会发生在进程与RouDi心跳超时之后。
KEEPALIVE 命令
关于心跳这个命令,在iceoryx的 release_2.0分支下是一条独立的命令 KEEPALIVE, 由runtime定时发送给RouDi,但是在master分支下,已经取消了这个命令,而是在REG命令处理的时候直接分配一段内存存放心跳信息,后面Runtime直接向这块内存更新心跳信息。
其他命令
此外其他的命令我在使用订阅发布机制的情况下并没有观察到,这里我不做描述,可以自行查阅代码,就在 RouDi::processMessage这个函数里面。
RouDi
功能入口
RouDi是iceoryx整体架构中的中心节点。RouDi的代码入口在 iceoryx_posh\source\roudi\application\roudi_main.cpp. 做的事情简单说是从配置文件加载配置,然后传入IceOryxRouDiApp类,并启动。
1 | int main(int argc, char* argv[]) noexcept |
创建内存
RouDi在启动的时候做的最重要的一件事情是创建共享内存,他是怎么来创建的呢?
对象关系
首先来找出创建内存相关的类或对象,我根据源码上的类关系,梳理成下面的类(或者对象)关系:
1 | IceOryxRouDiApp |
- 这里面两处
PortManager是引用同一个,两个PortPool也是引用的同一个,三处IceOryxRouDiMemoryManager也是引用的同一个。 - 这里面多个Block都是继承
MemoryBlock基类,并最终被放到vector<MemoryBlock*>这个数组里面; - 这里面
PosixShmMemoryProvider是继承MemoryProvider接口的,并最终被放到vector<MemoryProvider*>这个数组里面。
这个关系中还是看不出重点,我们来看一下初始化之后这些类(或者对象)的关系变成什么样:
1 | IceOryxRouDiApp |
可以看出,这里面 IceOryxRouDiMemoryManager下面挂了(引用了)一大堆的东西,有port相关的有block相关的;而反过来被多个对象引用的则是 PortPoolData,直接或间接地被 PortManager、IceOryxRouDiComponents、RouDi引用。因此这里面最核心的类就是 IceOryxRouDiMemoryManager和PortPoolData了。IceOryxRouDiMemoryManager在这里的作用是什么呢,他是负责创建 PortPoolData和其他的内存的。
这样就串起来了:PortManager、IceOryxRouDiComponents、RouDi引用 IceOryxRouDiMemoryManager和 PortPoolData,而 IceOryxRouDiMemoryManager又是创建 PortPoolData和其他的内存块。
内存分配
触发内存分配的函数调用来自 IceOryxRouDiMemoryManager::createAndAnnounceMemory(), 并最终调用到 MemoryProvider::create(), PosixShmMemoryProvider继承自 MemoryProvider::create(),因此调用的也同时是 PosixShmMemoryProvider::create()。如下:
1 | IceOryxRouDiMemoryManager::createAndAnnounceMemory() |
MemoryProvider::create 内部做了两件事,一个是计算出他下面挂的 vector<MemoryBlock*>中全部block所需的内存之和,并向系统申请一整块的内存,由于我们在 PosixShmMemoryProvider类中,因此他申请内存的方式就是使用共享内存,在linux中就会在/dev/shm/下面创建一个共享内存文件,叫iceoryx_mgmt。另一个事是从这一大片内存中切切切,切一段给这个MemoryBlock,切一段给那个MemoryBlock,切的时候都是字节对齐的,也是一段接一段连续地切的。当前,申请内存的时候已经计算上字节对齐所需要的额外的字节数的。
1 | expected<void, MemoryProviderError> MemoryProvider::create() noexcept |
注意这里只是申请了内存,可以认为是一段裸的内存。由于iceoryx设计上是不允许重复使用共享内存文件的,每次启动都会去清理旧的内存并新建新内存,因此这里的共享内存文件一定是新创建的,新建后被自动初始化为全零,这是共享内存默认的行为。
内存初始值填充
内存在上面被创建以后,初始内存是被初始化为0,接下来就需要做内存值的填充。
1 | IceOryxRouDiMemoryManager::createAndAnnounceMemory() |
announceMemoryAvailable函数做的事情,就是依次调用他下面挂的 vector<MemoryBlock*>中每个block的 onMemoryAvailable函数,如下:
1 | void MemoryProvider::announceMemoryAvailable() noexcept |
最终结果是每个 MemoryBlock的 onMemoryAvailable函数被触发,每个 MemoryBlock负责把自己负责的那片内存进行初始化。
比如portPoolBlock他初始化或者说填充这片内存的方式,就是在这片地址中实例化一个对象。
1 | void PortPoolMemoryBlock::onMemoryAvailable(not_null<void*> memory) noexcept |
但值得展开讲的是另一个block的初始化,这个blcok是segmentManagerBlock,他是专门负责做内存池管理的,下面展开。
创建内存池
segmentManagerBlock在初始化的时候,首先也是在这个指定的内存地址上实例化一个管理对象,但是他这个管理对象并没有占满属于这个block的全部内存,后面还有一长段空间,存放的是什么呢,是若干个无锁队列。这个无锁队列用来干什么的我们下面来讲。
pool管理
在iceoryx_posh\etc\iceoryx\roudi_config_example.toml这里存在一个RouDi的配置文件:
1 | # Adapt this config to your needs and rename it to e.g. roudi_config.toml |
这个文件里面最主要的是定义了一个内存段的配置,一个内存段是多个内存池的集合,每个内存池又是固定大小的内存块的集合。其中每个[[segment]]对应一个内存段,每个[[segment.mempool]]代表内存段中的一个内存池。[[segment.mempool]]中size代表内存块大小,count达标内存块个数。
那么iceoryx为了管理内存池中每个内存块的使用情况,使用无锁队列来进行管理,每个[[segment.mempool]]对应一个无锁队列,这个无锁队列的队列长度就是[[segment.mempool]]中count的大小。比如上面这份配置中,iceoryx需要7个无锁队列,第一个队列的长度是10000,第二个队列的长度是5000,以此类推。
segmentManager在实例化一个对象后,其后面紧接着存放的就是上面的无锁队列。
pool创建
那么segmentManager实例化的管理对象还做了别的什么呢?
segmentManager最主要的是要组织好内存段和内存池的管理,这里涉及到3个层级的内存:[总内存]->[内存段]->[内存池]。反映在源码上,我们找出来下面几个关键的类,SegmentManager即可代表总内存;MePooSegment代表内存段,MemoryManager代表内存段下的内存池;MemPool代表内存池。也就是这样的层级:[SegmentManager]->[MePooSegment+MemoryManager]->[MemPool]。
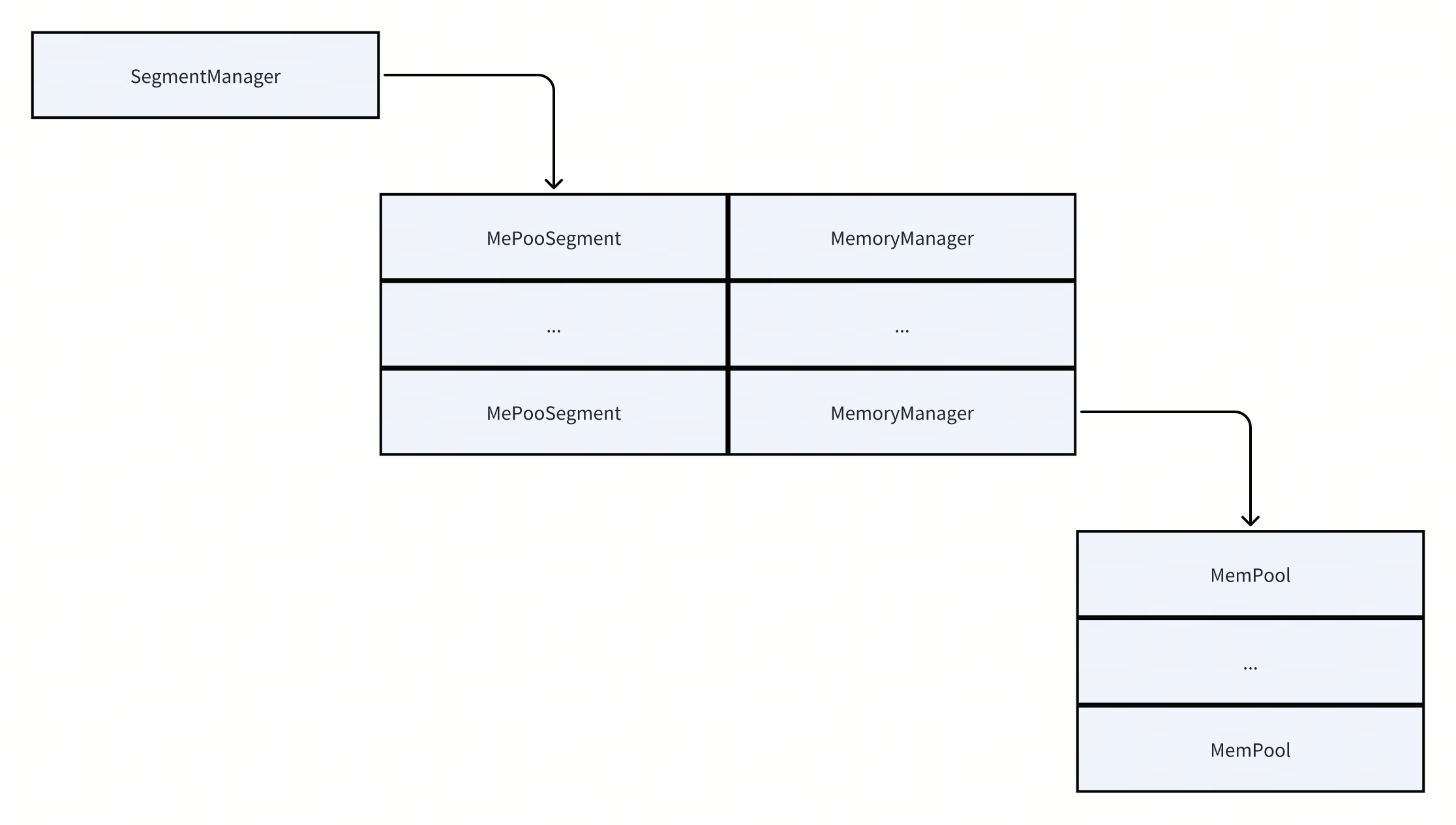
1 | class SegmentManager |
那么这些类定义里面,有两个重要的信息,一个是MePooSegment::m_sharedMemoryObject,这是一个非常重要的成员。我们已经知道MePooSegment代表一个内存段,他可能会很大,大到几个G。iceoryx中一个内存段对应一个MePooSegment对象,而一个MePooSegment对应一个m_sharedMemoryObject对象,因此实际上一个内存段会对应一个m_sharedMemoryObject对象,也就是会对应一个共享内存文件,通过这个共享内存的创建完成内存池的创建。
iceoryx没有把m_sharedMemoryObject整合到前面统一创建的整个内存段中,而是设计为一个独立的内存段,我个人理解是他要把管理和数据两类内存分开,前面统一创建的一片内存都是用于管理的目的,对应的共享内存文件名叫iceoryx_mgmt,可以看出是用于管理作用的。 而现在这里的内存是单纯作为内存池供用户存放业务数据的,作用上比较独立,所以就适合分开。
m_sharedMemoryObject对应的共享内存文件名是你当前的用户名,比如你是root用户,那么对应的文件在linux系统中就是/dev/shm/root。那么如果多个MePooSegment对象对应的文件名又分别是什么呢?事实上当前的iceoryx并没有在事实上支持多个MePooSegment对象!
虽然不论从数据结构层面和配置文件层面都是支持多个内存段的,但是实际使用上我发现并不支持,如果我配置了多个[[segment]],那么创建的共享内存文件只包含最后一个内存段的空间大小,并且功能上也不再正常。
上面类图中另一个重要信息是MemoryManager中有m_memPoolVector和m_chunkManagementPool,其中m_memPoolVector可以理解是对应了内存池。m_chunkManagementPool又是什么呢?
我们知道内存池都是固定大小的内存块,内存的块数也是确定的。每一块内存被申请使用时,需要通过引用计数确保内存被正确的释放,那么就需要有个memory wrapper这样的角色对内存地址进行封装,把内存地址和引用计数封装在一起。比如下面来自源码的类定义:
1 | struct ChunkManagement |
每一个内存块都需要一个memory wrapper进行管理,因此iceoryx最多需要N个memory wrapper进行管理,N是每一个pool的内存块个数的总和。上面类定义中m_chunkManagementPool就是指向一个分配ChunkManagement的内存池,这个内存池追加在上面无锁队列的后面,跟m_memPoolVector的内存池指向独立的共享内存文件不同,这点在后面的内存分配图中可以看出。
完整的内存分配图
下图是对上面内存分配的完整总结,大片的内存总共是两片,一个是文件名为iceoryx_mgmt的用于管理的内存,内存切分成多个不同的区域分给不同的对象管理;一个是文件名为用户名的用作内存池的内存,其大小受到配置文件的影响。
(右键-在新标签页中打开图片,可以看得更清晰)
Runtime
初始化 initRuntime
实例化 PoshRuntimeImpl
首先初始化Runtime的代码是:iox::runtime::PoshRuntime::initRuntime(APP_NAME);.
跟踪到内部后可以看到他就是实例化PoshRuntimeImpl并调用其构造函数, 但是他实例化的代码相对复杂,这里稍微展开一下。
实例化的核心代码:
1 | PoshRuntime& PoshRuntime::defaultRuntimeFactory(optional<const RuntimeName_t*> name) noexcept |
这段代码里面创建了两个静态变量,一个是buf, 一个是staticLifetimeParticipant。其中buf就是一段内存对齐的buffer,他跟char buf[sizeof(PoshRuntimeImpl)]是差不多的。这个buf就是被创建来做为PoshRuntimeImpl的载体的,并在new (&buf) PoshRuntimeImpl(name);中被执行实例化。staticLifetimeParticipant则是为了管理PoshRuntimeImpl的析构时机, staticLifetimeParticipant在被析构的时候会检查这是不是最后一个ScopeGuard(staticLifetimeParticipan的类型), 如果是就析构PoshRuntimeImpl。
1 |
|
也就是说Runtime的实例PoshRuntimeImpl在第一次调用initRuntime的时候被实例化,实例化的对象存放在一段static的buf中;而PoshRuntimeImpl的析构则是在全部ScopeGuard被析构之后才被析构,所有在其生命周期中需要确保PoshRuntimeImpl存在的模块,都应该人为调用static ScopeGuard staticLifetimeParticipant=getLifetimeParticipant()在他的cpp中,以确保PoshRuntimeImpl能覆盖该模块的生命周期。
这种方式比较精确的控制了全局变量的构造和析构时机, 比简单的static PoshRuntimeImpl impl;要灵活和安全。这种方式有一个专门名字叫nifty counter. 可以参考c++ 全局变量初始化及惯用方法之 Nifty Counter.
PoshRuntimeImpl构造函数
PoshRuntimeImpl的构造函数中主要做两个事情,一个是IpcRuntimeInterface::create,一个是SharedMemoryUser::create.
IpcRuntimeInterface::create中做的事情依次为:
- 尝试建立与RouDi的Ipc连接, 在linux中, 其通过UnixDomainSocket来连接到RouDi的。
1 |
|
尝试的意思是,连接,但是先容许错误, 因为RouDi可能此时还没有启动。
-
建立一个属于自己的DomianSocket,如果创建失败,会立即返回错误。成功后,会创建以runtimeName为文件名的DomianSocket, runtimeName就是initRuntime()函数中用户传入的参数。
-
如果1中连接连接失败, 就持续重试,直到超时返回错误,或者连接成功。
-
通过1中建立的连接,向RouDi发送一条REGISTER请求。请求中携带了runtimeName,因此, RouDi收到后,能够拼出此runtime的DomianSocket路径。
-
在2中创建的socket中等待RouDi对REGISTER的响应,直到超时返回,或者成功收到响应。收到响应后检查响应内容, 如果符合预期,拿到了相关的信息, 表示注册成功。 否则表示注册失败。成功之后完成
IpcRuntimeInterface::create过程, 失败的话,就从第3步循环, 直到整个过程超时。
所以如果IpcRuntimeInterface::create返回成功, 那就表示runtime已经成功与RouDi建立连接, 并且经过一轮交互,注册成功了。
注册成功后,接着就是执行SharedMemoryUser::create.
SharedMemoryUser::create做的事本质上是把RouDi打开过的共享内存文件, 同样打开一遍. 前面我们梳理内存管理对象的时候有过这个关系: [总内存]->[内存段]->[内存池], 其中总内存和内存段是内存管理的对象, 他们位于叫xxx_management的以management为后缀的内存文件中, 而内存池, 则是实际用于分配的内存片段, 位于单独的xxx_username以你的实际用户名为后缀的内存文件中.
1 | 这是基于2025年初master分支编译的linux版本RouDi,运行后生成的两个对应的共享内存文件. |
打开的过程是这样的:
-
打开_management为后缀的共享内存文件. 文件名是RouDi和Runtime用一致的规则拼接的,所以是一致的.
-
接着用打开的文件的基地址加上RouDi在response中响应回来的offset值,来定位到[总内存]这个管理对象的地址,并把地址强转成mepoo::SegmentManager*类型,来完成mepoo::SegmentManager对象的构造.
-
接着从SegmentManager中拿到[内存段]列表, 每个[内存段]对应一个共享内存文件, 于是打开对应的这个内存文件. 也就是以用户名为后缀的这个文件.通常[内存段]只用到一个, 所以上面我们ls出来只有一个用户名后缀的文件, 这一个内存文件包含了全部的内存池.
-
打开的这些内存文件,他的地址是怎么管理的呢, 他是把这个文件的地址跟一个segmentId进行关联,保存在全局的容器里面, 后续涉及获取这个内存地址的,都采用传入segmentId的方式进行获取.
借内存 loan
loan内存经过的步骤:
-
向RouDi申请创建Publisher, RouDi回复成功或者失败, 如果成功,就返回一个内存offset,对应了PublisherPortData对象的内存地址.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33PublisherPortUserType::MemberType_t*
PoshRuntimeImpl::getMiddlewarePublisher(const capro::ServiceDescription& service,
const popo::PublisherOptions& publisherOptions,
const PortConfigInfo& portConfigInfo) noexcept
{
...
auto maybePublisher = requestPublisherFromRoudi(sendBuffer);
...
return maybePublisher.value();
}
expected<PublisherPortUserType::MemberType_t*, IpcMessageErrorType>
PoshRuntimeImpl::requestPublisherFromRoudi(const IpcMessage& sendBuffer) noexcept
{
IpcMessage receiveBuffer;
if (sendRequestToRouDi(sendBuffer, receiveBuffer) == false)
{
...
}
else if (receiveBuffer.getNumberOfElements() == 3U)
{
...
if (stringToIpcMessageType(IpcMessage.c_str()) == IpcMessageType::CREATE_PUBLISHER_ACK)
{
...
// using MemberType_t = PublisherPortData;
// RouDi返回的是PublisherPortData类型
return ok(reinterpret_cast<PublisherPortUserType::MemberType_t*>(ptr));
}
}
} -
基于1中创建的PublisherPortData对象, 我们调用
PublisherPortData::m_chunkSenderData::m_memoryMgr::getChunk(xxx)来获取一块满足大小的chunk也就是一块内存. 这里m_memoryMgr对象负责管理一个共享内存文件, 里面的对象被分成多个不同chunk size的pool, 也就是上面讲到过的内存管理方案([总内存]->[内存段]->[内存池])中内存段的管理对象,这个函数会遍历每一个不同chunk大小的pool, 遇到满足size的pool,就从pool中申请一块, 这个pool中没有空闲了,就返回不错, 不向更大的pool申请.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18expected<SharedChunk, MemoryManager::Error> MemoryManager::getChunk(const ChunkSettings& chunkSettings) noexcept
{
......
for (auto& memPool : m_memPoolVector)
{
uint64_t chunkSizeOfMemPool = memPool.getChunkSize();
if (chunkSizeOfMemPool >= requiredChunkSize)
{
chunk = memPool.getChunk();
memPoolPointer = &memPool;
aquiredChunkSize = chunkSizeOfMemPool;
break;
}
}
....
}
可以看出第一步只要做一次, 第二步则是loan一次执行一次. 第一步在publisher的构造函数中的得到执行, 第二步在每次调用loan函数时候得到执行.
发数据 publish
发数据的过程, 核心还是在上面创造的PublisherPortData对象, 在PublisherPortData::m_chunkSenderData::m_queues中保存了数据发送的目标队列,也就是subscriber队列.我们遍历这个队列,然后把我们要发送的chunk塞进队列中, 如果存在对应的condition_variable, 就同时触发一次唤醒.
1 | template <typename ChunkDistributorDataType> |
对于理解逻辑, 代码只要看其中的大意, 他代码用了大量的模板, 要全部理清楚,要费很多时间.
publish这部分逻辑上面CREATE_CONDITION_VARIABLE 命令小节中已经梳理过一遍, 包括subscriber的逻辑也已经被包含在一起了. 如果感兴趣可以往回回看那小节.
下一步
iceoryx目前比较成熟, 零拷贝的设计也很好, 但是他存在中心节点这一点比较有争议, 也一定程度上影响他的应用.
iceoryx目前社区已经在开发iceoryx2, 他重构了设计, 移除了中心节点这一设计. 值得关注.
时隔一年多,在2026年1月,零拷贝通信框架iceoryx2原理解析已经发布.