零拷贝通信框架iceoryx2原理解析
零拷贝通信框架iceoryx2原理解析
简介
在之前的文章SOA框架iceoryx原理解析中, 我们讲解了iceoryx的架构、原理、交互,并进行源码的分析,在那篇文章最后我提到要关注iceoryx2这款通信框架, 现在我们来把iceoryx2的分析给补上。
iceoryx2,缩写为iox2,中文名叫冰羚2, 所以当后面提到冰羚2、iox2、iceoryx2的时候,他们都指代的是iceoryx2.
冰羚2与冰羚一样,是一款基于共享内存的零拷贝的通信框架,他通过对共享内存文件读写的封装和操作,实现了同一主机内的进程之间的数据传输。他与冰羚最主要的差别是冰羚2采用了去中心化的架构设计,消除了单点故障分险。早期的冰羚2只支持rust语言, 只支持linux系统,随着版本迭代, 如今已经支持c/c++/rust/python/c#。下面是iceoryx2的整体架构图:

图片来自Introduction
从图中可以看出,iceoryx2支持各种操作系统, 支持各种编程语言, 同时既支持iox2的app之间的通信,也支持通过扩展来接入到DDS和ROS等通信网络。
这是iceoryx2的整体架构,也可以说是架构愿景, 因为其中有些是还没有实现的, 就比如支持的语言目前2026年1月只有c/c++/rust/python/c#,操作系统也只是刚支持上linux/macos/qnx/win。在与外部网络的接入方面,据我所知,ros2和dds和zenoh在2025年都已经有方案来实现对iox2的接入支持,图中其他的autosar和smoltcp对iox2的使用我并不了解。 尽管如此,随着不断迭代,更多特性被加入,iceoryx2的代码已经很庞大了,要深入理解已经不太容易。我们下面就选择他早期的一个版本来深入了解一下。
整体代码结构
我们使用iceoryx2-0.1.0的版本来进行分析, 这是他在github仓库中打的第一个tag,此时代码结构相对简单,没有复杂的特性, 仅保留核心逻辑, 非常适合做原理分析。
iceoryx2-0.1.0的目录结构如下:
其中最重要的是4个目录,分别是iceoryx2/iceoryx2-bb/iceoryx2-cal/iceoryx2-pal, internal目录里面是一些脚本非核心。这4各目录分别是什么作用呢?

其中pal代表的是Platform Abstraction Layer的意思,表示平台抽象层,是对不同操作系统的一层抽象,由于当前支持的linux/macos/qnx/win都支持posix, 所以当前pal下就是对posix做了一层封装。
bb代表的的Building Blocks的意思,这一层实现的是一些工具或者组件,包括vector容器,queue队列,log日志,内存分配器pool_allocator,等等。对照Building Blocks这个名字,我们可以把这些理解成造房子的砖头。
cal代表的是Concept Abstraction Layer的意思, 表示概念抽象层,这一层开始有了通信相关的概念,比如share_memory共享内存, shm_allocator共享内存分配器,zero_copy_connection零拷贝连接, event事件,serialize序列化,等等。这一层相当于是通信用的模块,bb类比砖头,cal就可以类比成一面墙,一扇窗,一口衣柜。
iceoryx2这一层是通信的实现层加接口层,这一层借助cal层来完成最后通信组件的组装和实现,实现了publisher,subscriber,service等核心组件(0.1.0版本还没有node组件)。同时这些组件也是被用户直接操作的接口, 因此这一层同时也是接口层。
接下来,我会选择其中最重要的几个点进行讲解,分别是pool_allocator内存分配器,share_memory内存对象,service服务组件,publisher发布者组件,subscriber订阅者组件,以及zero_copy_connection零拷贝连接, 通过了解这些对象, 我们能够知晓通信框架是如何被建立的,以及通信是如何实现的。
pool_allocator内存分配器
内存布局
rust语言中有个 use std::alloc::Layout;这个是做什么的。
1 | use std::alloc::Layout; |
layout代表的是内存块的信息, 包括内存块的大小,和这块内存的字节对齐要求。
上面Vec<T> 本质上是一个三元组(胖指针结构):
1 | pub struct Vec<T> { |
在 64 位系统上:
*mut T(指针):8 字节len(usize):8 字节cap(usize):8 字节
总计:8 + 8 + 8 = 24 字节.
layout在alloc和dealloc的时候都要传递进去,alloc的时候传递比较好理解,allocator需要知道内存对齐以及需要知道要分配多大的内存。那为什么dealloc的时候也需要传递layout呢?
我们知道c语言中malloc出来的内存,可以直接free, 不需要传递layout这种类似的结构。这是因为c语言的分配器把分配出来的内存大小隐藏在在分配出来的内存的头部:
1 | // 带头部信息的分配器 |
因此dealloc的时候通过把用户指针左移Header大小后就可以知道实际分配的内存大小了。
但是rust没有做这种内存布局的假设, 他允许allocator不需要Header前缀, 因此就需要额外来传递layout, 来获取这个实际分配的内存大小。比如我们可以实现一个基于内存块大小的内存池, 申请的时候, 申请32-size就返回32大小的内存块, 而不必返回一个实际是32+x的内存块。比如实现内存池,按需返回block块, 申请1k就返回1k的,而不是因为要加x额外空间就返回2k的block:
1 | // 按大小分类的分配器 |
内存分配器的接口都会伴随着layout的传递。
内存分配器
接口定义
BaseAllocator 接口, 定义allocate和deallocate接口:
1 | pub trait BaseAllocator { |
Allocator接口,定义grow和shrink接口:
1 | /// Allocator with grow and shrink features. |
接口实现
基于内存池并实现内存分配器接口的内存分配器实现 iceoryx2_bb_memory::pool_allocator::PoolAllocator如下:
1 | pub struct PoolAllocator { |
所以可以看出iceoryx2_bb_memory::pool_allocator::PoolAllocator实现了内存分配/释放和内存增长/缩减的功能,是一个满足功能要求的对象。
但是这还不止,我们从前面分层架构中可知, bb层的对象还不能被iceoryx2层直接使用, 而是需要经过cal层的封装, 因此cal层进行了如下封装:
1 | // 接口 iceoryx2_cal::shm_allocator::ShmAllocator |
1 | // 实现:iceoryx2_cal::shm_allocator::pool_allocator::PoolAllocator |
iceoryx2_cal::shm_allocator::pool_allocator::PoolAllocator本质上就是对iceoryx2_bb_memory::pool_allocator::PoolAllocator进行了封装, 并重新暴露了类似的接口, 把内存分配器从bb层提升到了cal层。
bb层和cal层的内存分配接口有个很大的差别, bb层申请和释放的是内存绝对地址(还是虚拟地址不是指物理地址), cal层申请和释放的是内存相对地址, 即相对一个base地址的offset。offset的设计是有用的,因为当同一个共享内存文件被多个进程打开时,他们的虚拟地址是不同的, 他们需要通过base地址加offset才能定位到同一个内存位置。
同时从new_uninit和init两个函数来说,iceoryx2_cal::shm_allocator::pool_allocator::PoolAllocator需要从外面输入内存基址base_address以及内存分配器allocator,这个base_address也就是待分配的连续内存块,allocator则是用于创建辅助数据结构的内存分配器。辅助数据结构的内存分配器也从外面传入,就可以实现base_address和辅助数据结构都在同一个共享内存对象/文件中。这样不同进程之间共享内存对象和内存分配器,只要共享一个内存文件,就可以是完整的。
分配器原理
内存分配器是怎么实现内存分配的呢?如果你不感兴趣,可以跳过。但是这是个有意思的环节, 能了解底层实现细节。
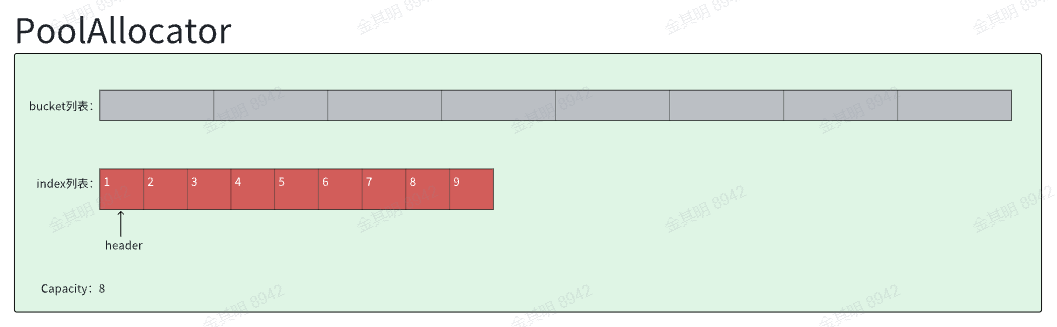
PoolAllocator内部有两个关键部分,第一个是bucket列表, bucket的每一个格子是字节对齐后的内存块列表, 内存块是连续分布的, 总共有Capacity块。
第二个部分是一个index列表+header指针,他们组成一个index分配器, 分配到哪个index, 就代表PoolAllocator分配的内存块是bucket列表中的第index个。
index分配器要展开来讲讲, 他初始的长度是Capacity+1, 每个格子是U32类型,正常只要Capacity个格子就够表达需要的index, 多出来的一个是为了操作的安全和便捷。这个U32的数组被模拟成一个链表, 比如初始状态,header的值是0, 表示链表指向数据的第0个格子, 然后第0个格子中的值是1, 表示这个链表的next节点是下标1, 下标1的格子中内容是2,表示1的next是2,以此类推。 这样初始状态下, 这就是一个从0到Capacity的顺序的链表。你会发现初始状态下, 没有一个格子的next指向第0个格子, 为什么呢?因为已经有header指向了0了, 所以不会有第二个指针指向0了。
每次分配一个index的时候,其实就是把header的值分配出去,然后 header就指向了这个模拟链表的下一个节点。分配出去一个index的时候, 这个bucket[index]指向的内存块就相当于分配出去了。比如,初始状态下, 首次分配显然会分配0,header会指向1。
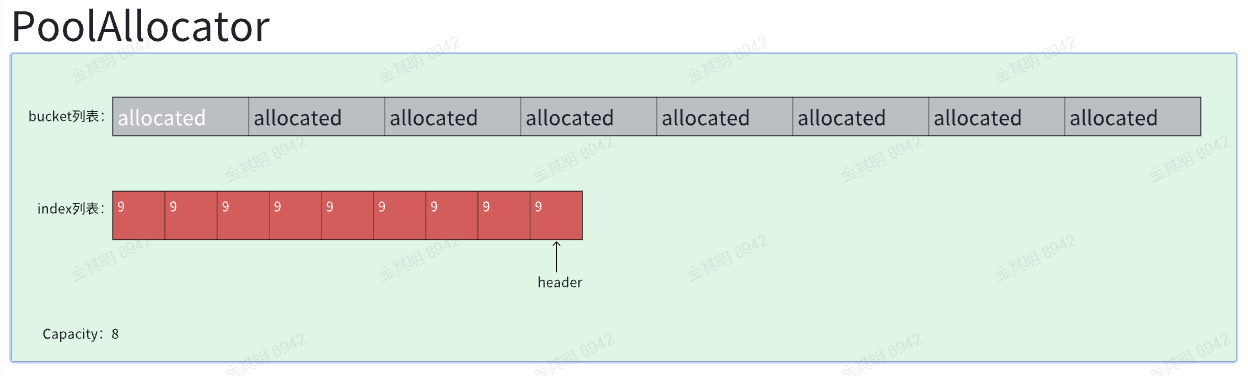
再比如极端情况,我分配Capacity次,header就指向了index列表的第Capacity格(base 0),也就是我们前面多分配的一个格子,最后一个格子, 示意图如下,已分配的格子被赋值成Capacity+1,指向链表尾,表示分配出去了:
当内存释放给PoolAllocator的时候,会传递要释放的内存块的index,这个index会被插入模拟链表的表头, 具体操作的话是把当前header的值填入这个第index个格子, 然后把index赋值给header,新header就指向了第index格子。
假设刚才我们从0到Capacity-1(base 0)分配出去了index值, 现在又从0到Capacity-1(base 0)释放index,这时候新的header会依次经历指向0,指向1,指向2 … 最终指向Capacity-1(base 0)格子。最终示意图如下:
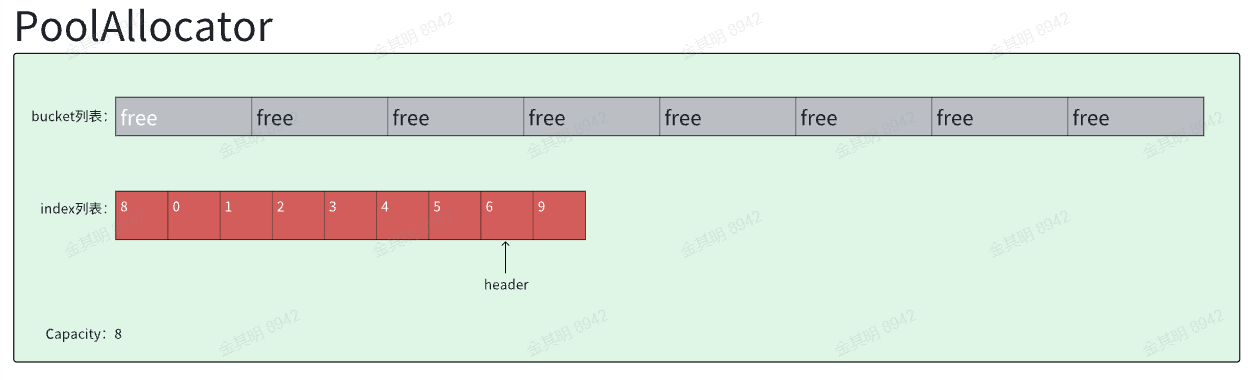
你会发现格子里面有0出现了, 但是没有了7,同样原因,这是因为这个时候header就是7.
关系图
总结一下这一堆Allocator之间的对应关系,如下:
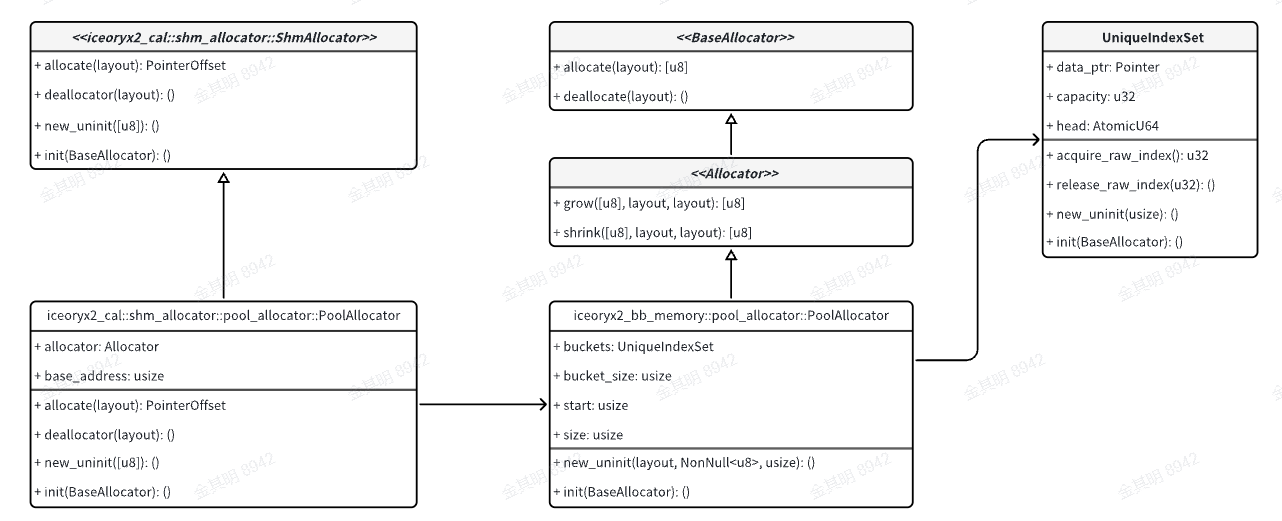
即iceoryx2_cal::shm_allocator::pool_allocator::PoolAllocator依赖iceoryx2_bb_memory::pool_allocator::PoolAllocator, iceoryx2_bb_memory::pool_allocator::PoolAllocator又依赖一个UniqueIndexSet结构。
UniqueIndexSet结构实现index分配(也就是上面介绍的分配器原理),iceoryx2_bb_memory::pool_allocator::PoolAllocator因此能实现payload的内存地址的分配,iceoryx2_cal::shm_allocator::pool_allocator::PoolAllocator又因此能实现payload的offset值的分配。
share_memory内存对象
bb层SharedMemory对象
现在先暂时忘记前面内存分配器,来从底往上梳理share_memory对象。
先是定义个iceoryx2_bb_posix::shared_memory::SharedMemory对象:
1 | pub struct SharedMemory { |
大概可以想到, 这个SharedMemory对应的就是一个共享内存文件。他具有如下接口:
1 | impl Drop for SharedMemory { |
也就是对一个共享内存文件的实现。
cal层Memory对象
接着定义了一个iceoryx2-cal::shared_memory::posix::Memory对象, 这个对象很重要, 他把bb层的SharedMemory对象和cal层的ShmAllocator对象囊括在了一起。
1 |
|
shared_memory字段就是bb层的一个SharedMemory对象,allocator就是cal层的一个ShmAllocator接口,我们从前面已经知道cal层的PoolAllocator就是实现了ShmAllocator接口的。
可见,cal层的Memory对象是一个自包含了内存和分配器的一个完备的内存对象。这个整合了内存分配器和内存对象的结构,对外表现的就是一块可以分配数据的内存, 因此他实现了以下SharedMemory接口:
1 | /// Abstract concept of a memory shared between multiple processes. Can be created with the |
可以想象的是, 为了实现内存分配, 需要实现一个关键的步骤, 就是把SharedMemory对象的地址传递给ShmAllocator。另外再来看我们前面提到的一段话:
1 | 同时从new_uninit和init两个函数来说,iceoryx2_cal::shm_allocator::pool_allocator::PoolAllocator需要从外面输入内存基址base_address以及内存分配器allocator,这个base_address也就是待分配的连续内存块,allocator则是用于创建辅助数据结构的内存分配器。辅助数据结构的内存分配器也从外面传入,就可以实现base_address和辅助数据结构都在同一个共享内存对象/文件中。这样不同进程之间共享内存对象和内存分配器,就是完整的。 |
可以知道除了传递payload的地址,还要传递辅助数据结构的内存分配器, 这个辅助数据结构也是我们前面分析过的,一段index数组,有多少块payload就有(多少+1)格的index。那么这个辅助数据结构和payload数据,是如何在这块共享内存上布局的呢?是这样的:

Memory对象内部会把内存分成3段, 第一段是AllocatorDetails结构,填充该共享内存本身的一些信息,包括allocator id, allocator指针,和payload起始地址的偏移量。第二段是辅助数据结构index列表,他以一个分配器的形式传给allocator。第三段是待分配的内存块,他把起始的地址传递给allocator。这样allocator如愿得到了index数组的内存分配器和内存块的地址。
补充一下,“第二段是index列表,他以一个分配器的形式传给allocator”, 这一段index列表也就是辅助数据结构是通过一个分配器的形式传给allocator的, 这个分配器实现的也是BaseAllocator接口(包含allocate和deallocate接口),其内部分配策略是一个相当简单的策略, 就是线性向上分配内存, 分配完为止,内存无法重复分配,释放内存则只释放一次,用来重置整段内存。对于index列表的场景来说, index列表是一次性分配整个数组,且不做释放, 所以这个简单的分配器就够用。
关系图
把内存的定义跟分配器的定义画到一起,大概是这样:
(右键-在新标签页中打开图片,可以看得更清晰)
cal层的Memory对象整合了bb层的ShareMemory对象和cal层的PoolAllocator,组合成了一个自包含内存和分配器的完整的内存对象。
service服务组件
service在通信框架中关联了一个通信实体的集合,他有一个service name与他关联,也有若干个publisher和subscriber与他关联。实际应用的时候我们通常把一个service与一个topic关联, 把topic name等于service name。这个topic的publisher和subscriber就是这个service的publisher和subscriber。
那么service跟前面的内存对象有什么关系吗,关系在于,与service关联的publisher和subscriber都会使用内存对象来进行数据传递。
关系图
与service相关的对象有点多,便于理解,先把关系图画出来如下:
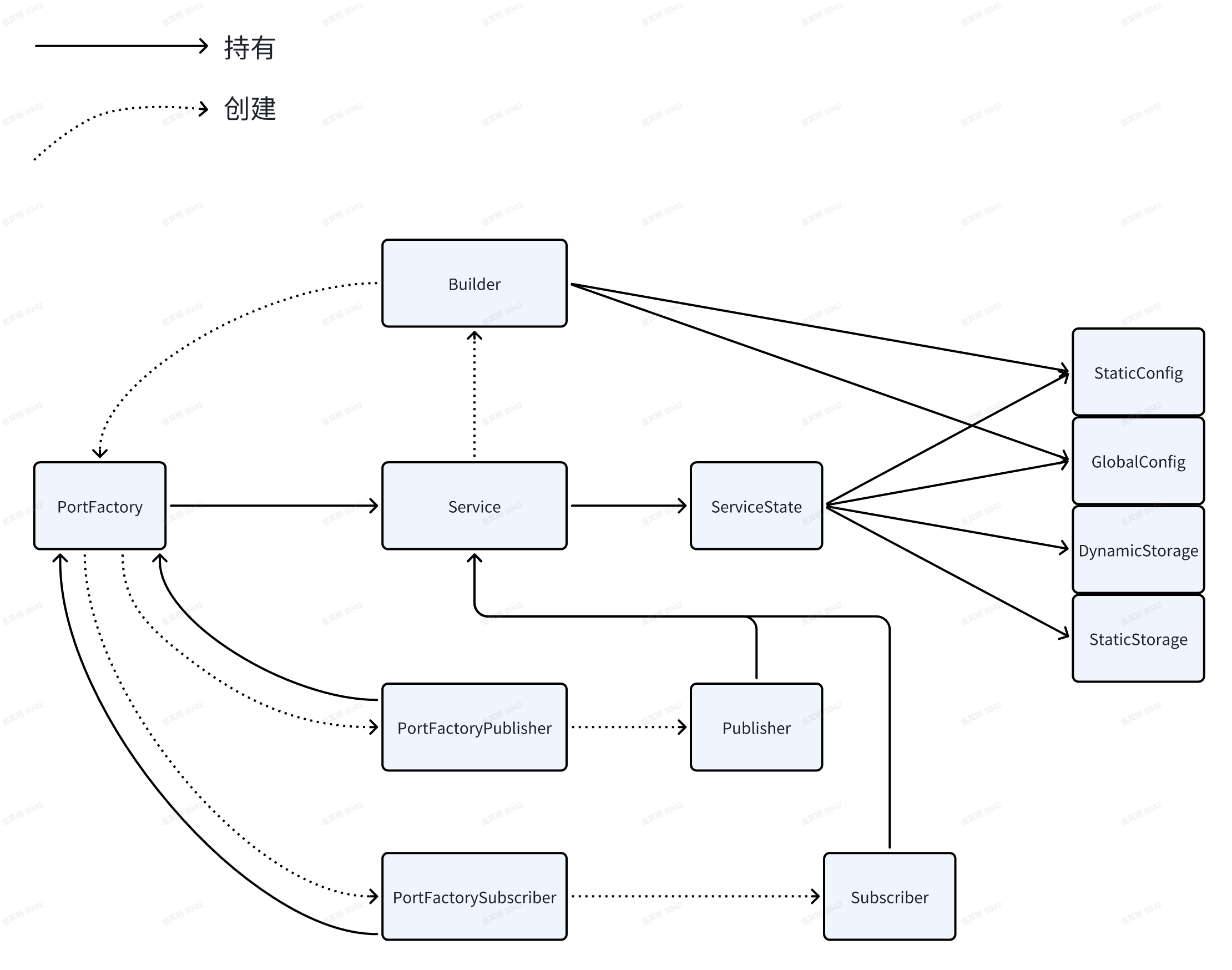
Service
1.Service拥有静态函数来创建Builder对象,Builder负载创建出PortFactory,PortFactory再最终负责创建出publisher和subscriber。
2.持有ServiceState对象包含service相关的全部配置信息。
第一点是一个静态接口,Service只是提供了一个命名空间的作用,第二点的作用更重要。Service对象最核心的作用其实是持有Service相关的配置信息。
ServiceState
ServiceState拥有service相关的全部配置信息, 分别有StaticConfig, GlobalConfig,DynamicStorage, StatisStorage。
static_config存的是服务名, 由服务名计算出的uuid,以及代表通信参数的messaging_pattern。
1 | // service::static_config::StaticConfig |
global_config包含了iceoryx2的整体的一些配置:
1 | [global] |
dynamic_storage保存了引用计数以及这个service对应的publisher们和subscriber们。他之所以是动态的, 就是因为他的内容是会被后续修改的, 当有新的publisher或者subscriber上线的时候他就会往里面追加新上线的id值。从代码看,DynamicConfig实现了新增publisher或者subscriber的id的接口,没有实现移除id的接口, 所以这个初版应该是没有实现下线时候移除id的功能的, 在新版本上是有实现移除功能的。
1 | // service::dynamic_config::DynamicConfig |
static_storage存的内容就是static_config相同的内容, 差别是这里把他存到了文件中去,文件默认为/tmp/iceoryx2/services/iox2_{uuid}.static_storage。
Builder
Builder拥有StaticConfig和GlobalConfig, 这两个也就是ServiceState当中的StaticConfig和GlobalConfig,ServiceState中DynamicStorage和StatisStorage也是从StaticConfig和GlobalConfig派生出来的。
Builder构建Service的构建过程,先get到global_config和service名,随后根据这两信息, 创建出static_config, 然后再根据static_config创建出dynamic_storage和static_storage, 最后把global_config|static_config|dynamic_storage|static_storage打包成ServiceState对象, 并根据ServiceState再创建出Service, 再根据Service创建出PortFactory。
这是一个我整理的Service-ServiceState-Builder三者之间的类关系图,黄色部分是Builder,紫色部分是ServiceState,绿色部分是Service:
(右键-在新标签页中打开图片,可以看得更清晰)
PortFactory
PortFactory持有Service对象,但他不负责直接创建publisher和subscriber,而是负责创建PortFactoryPublisher和PortFactorySubscriber,PortFactoryPublisher和PortFactorySubscriber再负责创建publisher和subscriber。
PortFactoryPublisher
PortFactoryPublisher反向持有PortFactory, 间接持有了Service对象,他负责创建Publisher。
PortFactorySubscriber
PortFactorySubscriber反向持有PortFactory, 间接持有了Service对象,他负责创建Subscriber。
Publisher组件
1 | /// Sending endpoint of a publish-subscriber based communication. |
port_id表示publisher对象的唯一id值,service表示此subscriber所属的Service。
data_segment内存对象
Publisher的data_segment字段表示存储payload的共享内存数据,包括loan还未send的和已经send的到异步队列中的,包括任一消费端正在消费的和待消费的, 从data_segment的数据片段个数的代码能看出来。
1 | // 计算publisher需要预留多少个payload片段 |
data_segment的类型Service::SharedMemory是通过类型重定义的,实际上就是上面章节中的iceoryx2-cal::shared_memory::posix::Memory内存对象类型。
subscriber_connections连接对象
subscriber_connections表示持有的与同一个Service下的Subscriber的连接,连接是一个抽象的说法,底层是一种共同持有一个共享内存文件的机制来关联在一起。关于connection的细节后面再单独小节展开。
subscriber_list_state表示SubsciberId的列表, 数据来自Service下面的dynamic storage。这个列表也是subscriber_connections构建的依据。
subscriber_connections的动态更新
publisher在每次send数据之前,会去更新连接列表,之后才去遍历连接,尝试向每一条连接写入数据。
1 | fn send_impl(&self, address_to_chunk: usize) -> Result<usize, ZeroCopyCreationError> { |
正如上面的代码注释所说, subscriber_connections连接对象正常应该是一个subscriber加入这个Service网络的时候被更新,不过现在是在每次send数据之前被更新。
更新的过程呢,就是根据service对象的dynamic_config信息,更新subscriber_list_state字段,之后根据subscriber_list_state字段更新subscriber_connections。
Subscriber组件
1 | /// The receiving endpoint of a publish-subscribe communication. |
service表示此subscriber所属的Service。
publisher_connections连接对象
publisher_connections表示持有的与同一个Service下的Subscriber的连接,连接是一个抽象的说法,底层是一种共同持有一个共享内存文件的机制来关联在一起。关于connection的细节后面再单独小节展开。
publisher_list_state表示PublisherId的列表, 数据来自Service下面的dynamic storage。这个列表也是publisher_connections构建的依据。
publisher_connections的动态更新
subscriber在每次receive数据之前,会去更新连接列表,之后才去遍历连接,尝试从每一条连接处读取数据。
1 | pub fn receive<'subscriber>( |
正如上面的代码注释所说, publisher_connections连接对象正常应该是一个publisher加入这个Service网络的时候被更新,不过现在是在每次receive数据之前被更新。
更新的过程呢,就是根据service对象的dynamic_config信息,更新publisher_list_state字段,之后根据publisher_list_state字段更新publisher_connections。
zero_copy_connection零拷贝连接
zero_copy_connection原理
在iceoryx2中, publisher和subscriber之间的数据传输是通过zero_copy_connection来实现的,说到connection,我们可能想到tcp,udp这样的,但这是基于共享内存的通信, 这里的连接肯定也是基于共享内存的。
zero_copy_connection的底层原理是一个publisher和一个subscriber共同持有一个共享内存文件, 文件名一般叫xxx.connection, publisher会持续往这个文件中写入新的数据片段的内存地址, subscriber会持续从这个文件中读取publisher新写入的数据的地址, 并进行后续的从地址获取数据的操作。这就相当于是在这个publisher和subscriber之间建立了一条数据传递的连接通道, 也就是为什么这被叫做connection的原因。
SubscriberConnections订阅者连接
对于publisher来说, 他要与多个subscriber通信, 因此iceoryx2中定义了一个SubscriberConnections结构被Publisher所持有 。
1 | pub struct Publisher<'a, 'config: 'a, Service: service::Details<'config>, MessageType: Debug> { |
SubscriberConnections的定义如下:
1 |
|
可以看到一个Connection包含一个Sender, 一个Sender包含一个SharedMemory对象,一个SharedMemory对应一个共享内存文件。publisher发送一条数据, 就是把数据地址写入到SharedMemory对象中。
connection的SharedMemory对象
我们来看看SharedMemory对象内部的结构:
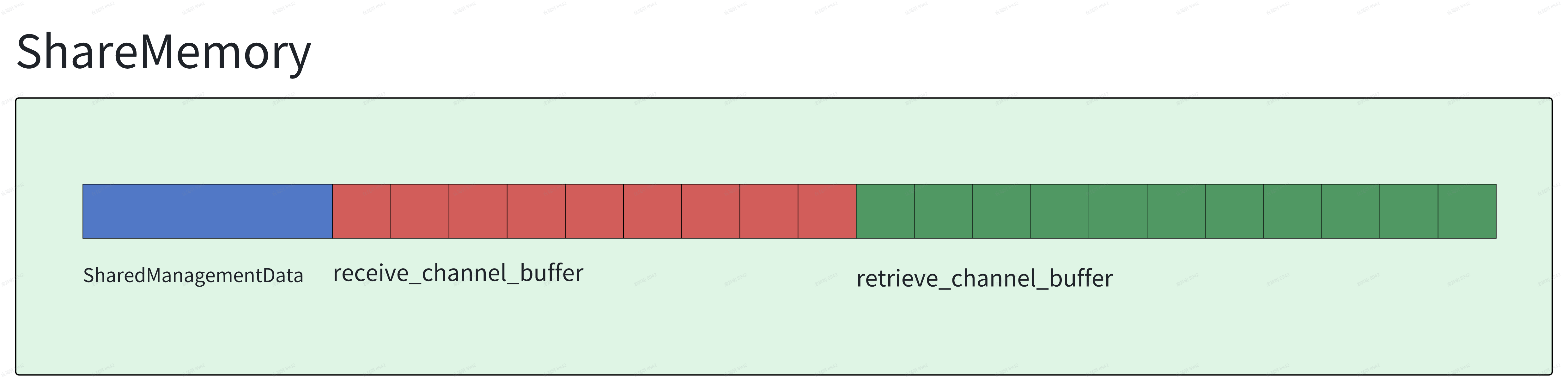
其中SharedManagementData是整个内存的管理结构,里面有两个关键字段receive_channel和retrieve_channel。receive_channel存放publisher新pub的数据(地址), channel容量是subscriber_max_buffer_size个。retrieve_channel存放subscriber消费完待释放的数据(地址), channel容量是(subscriber_max_buffer_size+subscriber_max_borrowed_samples)个。而receive_channel所需的地址空间就紧接着SharedManagementData, retrieve_channel所需的地址空间再紧接着receive_channel的地址空间。receive_channel字段与receive_channel的地址空间的关联,以及retrieve_channel字段与retrieve_channel地址空间的关联,稍等讲。
Sender是怎么操作这段内存的呢?Sender结构支持try_send/blocking_send/reclaim接口,try_send接口逻辑简单, 就是往receive_channel把内存地址push进去;blocking_send则先等待receive_channel有空,然后再把内存地址push到receive_channel;reclaim则从retrieve_channel中弹出一个地址,这个地址会在调用处被计算对应的引用计数, 计数减1,如果是0就释放给publisher持有的data_segment,让他用于重新分配。
对于receive_channel和retrieve_channel,他本身是一段内存区间, 我们要怎么理解他的push和pop操作呢?以retrieve_channel为例,一个channel首先是一个Queue对象:
1 | pub struct IndexQueue<PointerType: PointerTrait<UnsafeCell<usize>>> { |
这个对象有一个data_ptr执行数组存放队列的数据, 有个capacity表示队列的最大容量,有个write_position指向写入的下标, 一个read_position指向读的下标, write_position向上增加, read_position也向上增加, 超过容量就从0开始,形成一个环形队列。所以这是一个一读一写的环形队列, 原理是简单的,push和pop就是维护读和写的指针。
再看receive_channel,他跟retrieve_channel的对象拥有相同的结构体, 唯一跟retrieve_channel的差别是receive_channel在queue满的情况下允许滚动覆盖,而retrieve_channel在队列满的时候直接就返回false。现在我们来解答刚才暂时搁置的channel字段与channel的地址空间的关联,如果我们把receive_channel和retrieve_channel的内部指针也画在上面的图中,他大概是这样的:
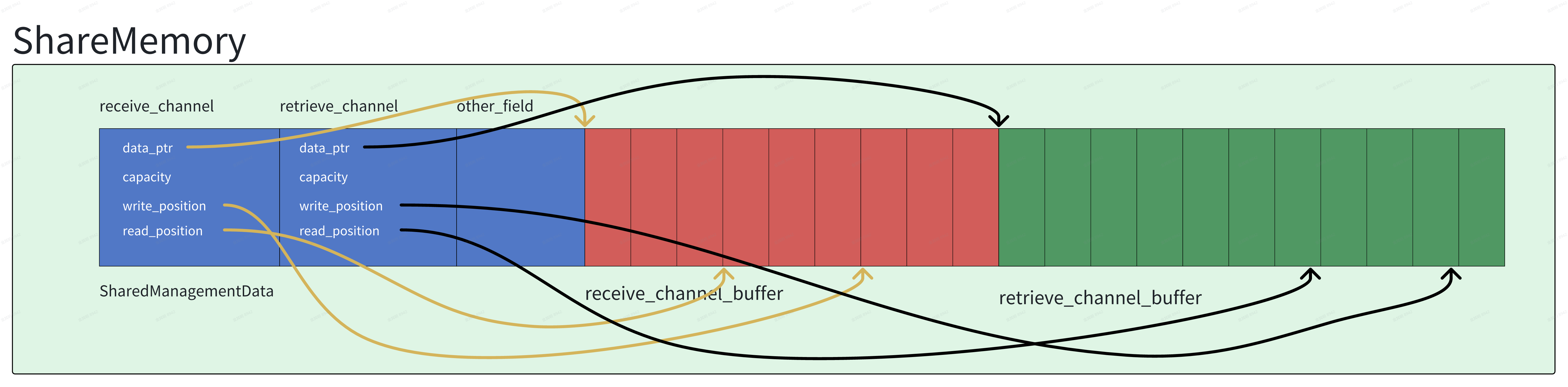
总结来说, publisher在某个时机会从每个connection中reclaim消费完的数据(这个时机是在publisher申请内存块loan的时候,这个不展开讲了),并在某个时机把数据地址塞到connection的receive_channel中去(这个时机是send的时候)。
PublisherConnections发布者连接
对于subscriber来说, 他要与多个publisher通信, 因此iceoryx2中定义了一个PublisherConnections结构被Subscriber所持有 。
1 | pub struct Subscriber<'a, 'config: 'a, Service: service::Details<'config>, MessageType: Debug> { |
PublisherConnections的定义如下:
1 |
|
PublisherConnections下面的connection跟SubscribeConnections下面的connection并不相同,PublisherConnection下面一共包含两个共享内存文件, 一个是data_segment字段,他实际指向Publisher对象下面的data_segment, 也就是存放payload数据的共享内存文件; 另一个是receiver.shared_memory字段, 他实际指向publisher的SubscriberConnection下面的sender.shared_memory,也就是存放传递中的payload数据的内存地址信息的共享内存文件, 也就是前面讲到的包含receive_channel跟retrieve_channel的内存对象。
一个subscriber他是如何读取数据的呢,他先从PublisherConnection中的receiver.shared_memory中获取待消费的数据的地址信息,随后根据这个地址信息, 从PublisherConnection的data_segment中获取这个地址对应的payload数据。核心代码如下:
1 | fn receive_from_connection<'subscriber>( |
关系图
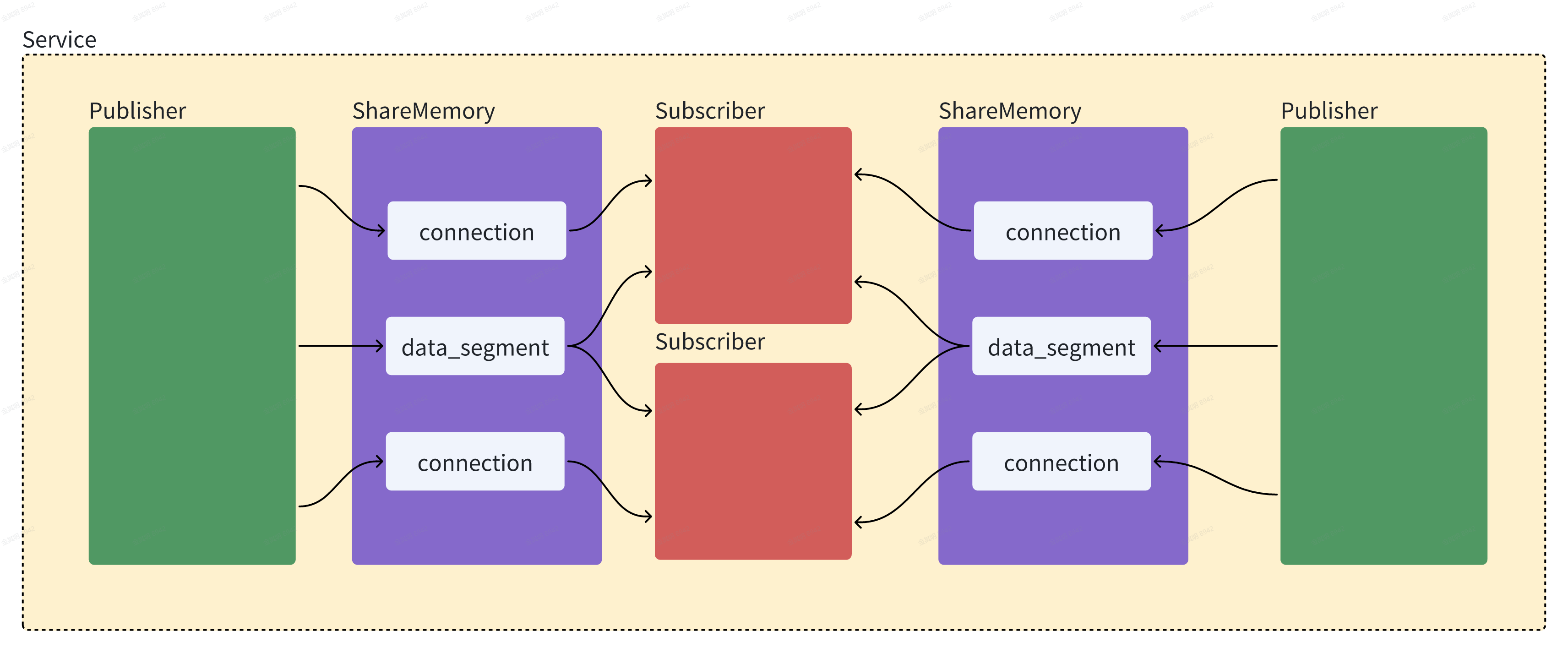
可以看到:
1.Publisher和Subscriber都会关联一个Service;
2.一个Publisher和一个Subscriber之间通过两个共享内存文件关联, 一个是connection文件, 一个是data_segment文件,connection存放传递中的数据地址, data_segment存放数据payload本身;
3.一个publisher只有一个data_segment文件,却有多个connection文件;
4.一个subscriber有相同个数的data_segment文件和connection文件;
通信过程
把上面connection相关的对象串起来后就是整个的通信过程:
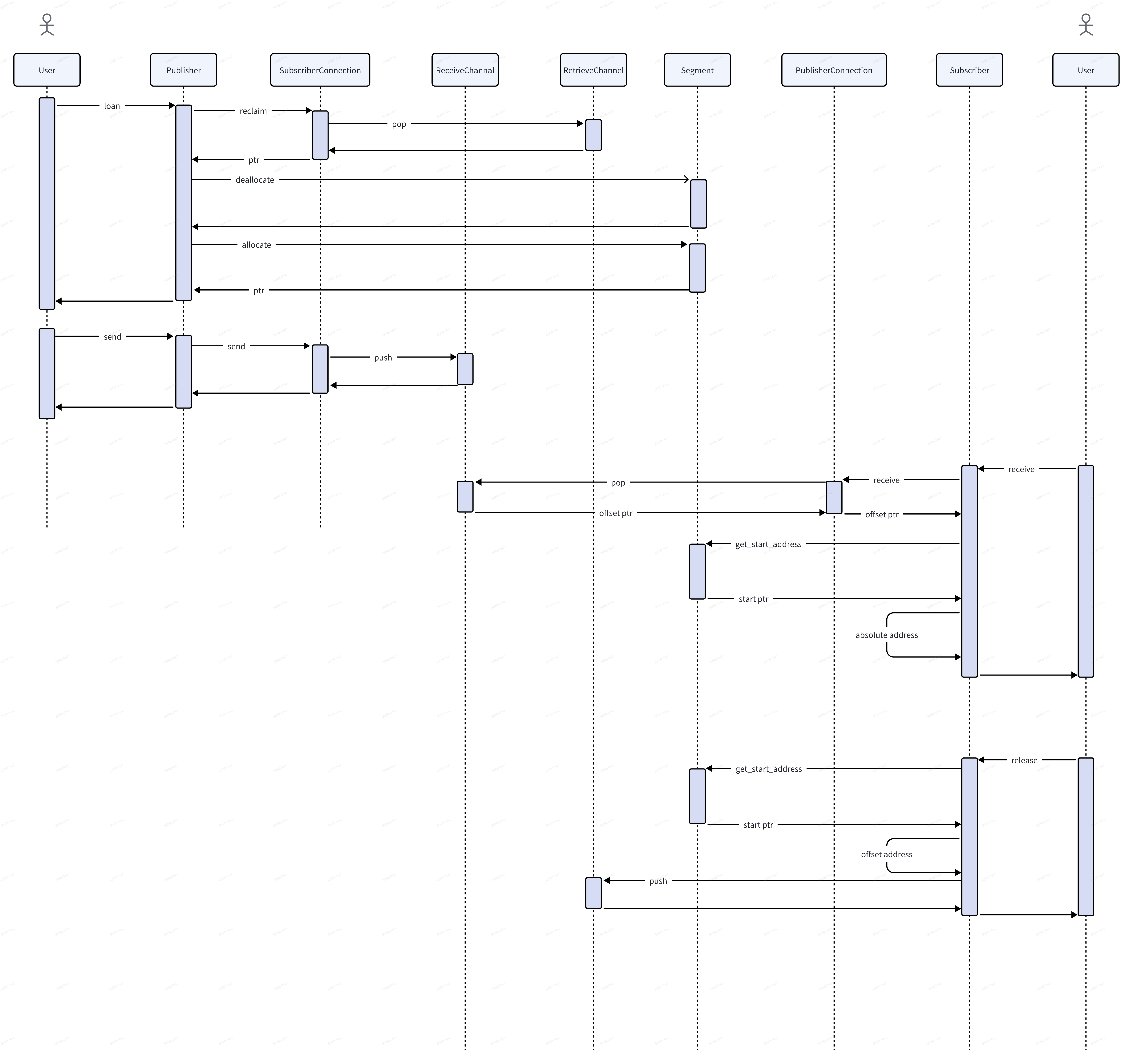
(右键-在新标签页中打开图片,可以看得更清晰)