树莓派搭建k8s集群
树莓派搭建k8s集群
简介
我们有很多时候需要搭建一个k8s集群,可能为了开发,可能为了测试,可能为了学习。在选择机器上可以有几个选择,一个是使用几台PC,一个是开几个虚拟机,一个是使用几个轻量的开发板。这里我主要以学习为目的,并且选择使用轻量开发板的方式,并且以最常用的树莓派作为代表,来搭建一个k8s集群。
由于主要以学习考试为主,这里暂时不考虑搭建单机集群的方式,因为没法接触到涉及多个节点的操作场景。
同时也不考虑k3s,我知道k3s是专为轻量设备而设计的,功能跟k8s基本是一样的,但是k3s和k8s只是功能基本相同,但是在使用和配置上,都有很多不同,并且使用的是完全分开的文档。k8s在使用上经常需要查在线文档的,即便对k3s的文档很熟悉了,在使用k8s的时候还是会存在查不到k8s文档的情况。因此学习k8s的时候,用k3s做练习是不合适的。
至于选择树莓派作为载体是个人选择,你可以选择使用pc或者选择使用虚拟机。如果你选择使用pc或者虚拟机,那么下面的章节中,【刷写系统】和【配置系统】会有差异,仅供参考。再之后的步骤则都是通用的。
最终我们将完成以下集群的搭建:
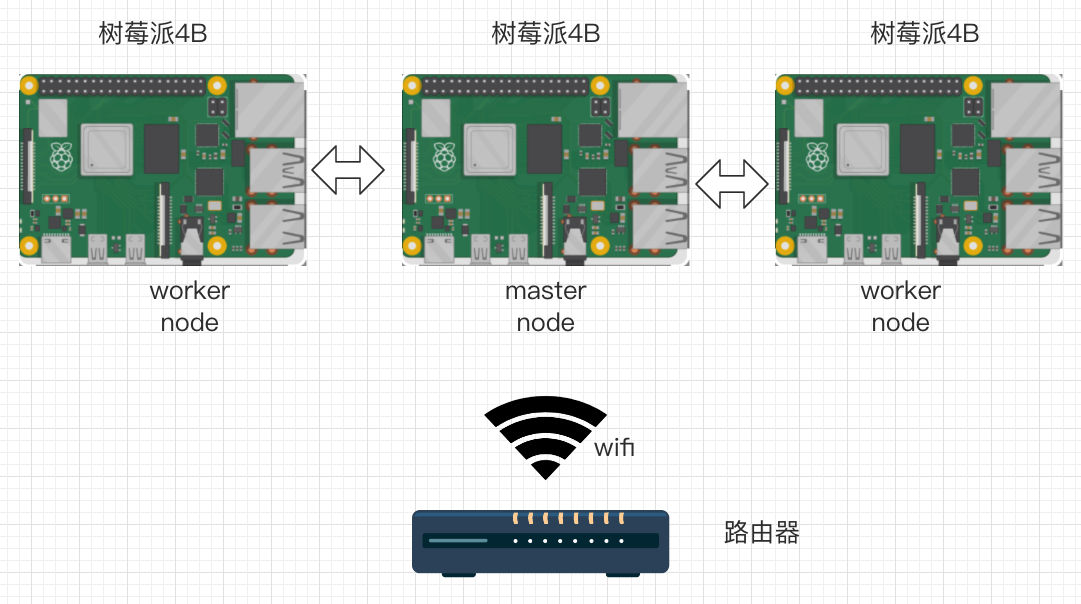
一个路由器,3个树莓派,树莓派通过wifi连接路由器,3个树莓派中一个master node,两个worker node。